Open Source Ajax Frameworks
* ThinWire - ThinWire is an development framework that allows you to easily build applications for the web that have responsive, expressive and interactive user interfaces without the complexity of the alternatives. While virtually any web application can be built with ThinWire, when it comes to enterprise applications, the framework excels with its highly interactive and rich user interface components.
* See all Open Source Ajax Frameworks
Open Source Aspect-Oriented Frameworks in Java
* AspectJ - AspectJ is a seamless aspect-oriented extension to the Java programming language, Java platform compatible and easy to learn and use. AspectJ enables the clean modularization of crosscutting concerns such as: error checking and handling, synchronization, context-sensitive behavior, performance optimizations, monitoring and logging, debugging support, multi-object protocols.
* See all Open Source Aspect-Oriented Frameworks in Java
Open Source Bloggers in Java
* The Roller Weblogger - A server-based weblogging software & a web application that is designed to support multiple simultaneous weblog users and visitors. Roller supports all of the latest-and-greatest weblogging features such as comments, WYSIWYG HTML editing, page templates, RSS syndication, trackback, blogroll management, and provides an XML-RPC interface for blogging clients such as w:bloggar and nntp//rss.
* See all Open Source Bloggers in Java
Open Source Build Systems in Java
* Maven - Maven is a Java project management and project comprehension tool. Maven is based on the concept of a project object model (POM) in that all the artifacts produced by Maven are a result of consulting a well defined model for your project. Builds, documentation, source metrics, and source cross-references are all controlled by your POM. Look here to see the full list of Maven's features.
* See all Open Source Build Systems in Java
Open Source ByteCode Libraries in Java
* BCEL - The Byte Code Engineering Library is intended to give users a convenient possibility to analyze, create, and manipulate (binary) Java class files (those ending with .class). Classes are represented by objects which contain all the symbolic information of the given class: methods, fields and byte code instructions, in particular.
* See all Open Source ByteCode Libraries in Java
Open Source Content Management Systems (CMS) in Java
* Apache Lenya - Apache Lenya is a Java-based Open-Source Content Management System. It is based on open standards such as XML and XSLT. One of its core components is Cocoon from the Apache Software Foundation.
* See all Open Source Content Management Systems (CMS) in Java
Open Source Cache Solutions in Java
* EHCache - EHCache is a pure Java, in-process cache with the following features: Fast,Simple, Acts as a pluggable cache for Hibernate 2.1., with Small foot print, Minimal dependencies, Fully documented and Production tested.
* See all Open Source Cache Solutions in Java
Open Source Charting & Reporting Tools in Java
* JFreeChart - JFreeChart is a free Java class library for generating charts, including:
* pie charts (2D and 3D)
* bar charts (regular and stacked, with an optional 3D effect)
* line and area charts
* scatter plots and bubble charts
* time series, high/low/open/close charts and candle stick charts
* combination charts
* Pareto charts
* Gantt charts
* wind plots, meter charts and symbol charts
* wafer map charts
* See all Open Source Charting & Reporting Tools in Java
Open Source Chat Servers in Java
* GujChat - GujChat is a new Chat System capable of managing multiple chat servers, each one serving different rooms and options for its users. One single installation delivers webmasters different templates, rooms, languages and configurations
* See all Open Source Chat Servers in Java
Open Source Code Analyzers in Java
* PMD - PMD scans Java source code and looks for potential problems like:
* Unused local variables
* Empty catch blocks
* Unused parameters
* Empty 'if' statements
* Duplicate import statements
* Unused private methods
* Classes which could be Singletons
* Short/long variable and method names
* See all Open Source Code Analyzers in Java
Open Source Code Beautifiers
* Jalopy - Jalopy is a source code formatter for the Sun Java programming language. It layouts any valid Java source code according to some widely configurable rules; to meet a certain coding style without putting a formatting burden on individual developers.
* See all Open Source Code Beautifiers
Open Source Code Coverage Tools in Java
* Cobertura - Cobertura is a free Java tool that calculates the percentage of code accessed by tests. It can be used to identify which parts of your Java program are lacking test coverage. It is based on jcoverage. Features of Cobertura:
* Can be executed from ant or from the command line.
* Instruments Java bytecode after it has been compiled.
* Can generate reports in HTML or XML.
* Shows the percentage of lines and branches covered for each class, each package, and for the overall project.
* Shows the McCabe cyclomatic code complexity of each class, and the average cyclomatic code complexity for each package, and for the overall product.
* Can sort HTML results by class name, percent of lines covered, percent of branches covered, etc. And can sort in ascending or decending order.
* See all Open Source Code Coverage Tools in Java
Open Source Collections Libraries in Java
* Commons Collections - Commons-Collections seek to build upon the JDK classes by providing new interfaces, implementations and utilities. There are many features, including:
* Bag interface for collections that have a number of copies of each object
* Buffer interface for collections that have a well defined removal order, like FIFOs
* BidiMap interface for maps that can be looked up from value to key as well and key to value
* MapIterator interface to provide simple and quick iteration over maps
* Type checking decorators to ensure that only instances of a certain type can be added
* Transforming decorators that alter each object as it is added to the collection
* Composite collections that make multiple collections look like one
* Ordered maps and sets that retain the order elements are added in, including an LRU based map
* Identity map that compares objects based on their identity (==) instead of the equals method
* Reference map that allows keys and/or values to be garbage collected under close control
* Many comparator implementations
* Many iterator implementations
* Adapter classes from array and enumerations to collections
* Utilities to test or create typical set-theory properties of collections such as union, intersection, and closure
* See all Open Source Collections Libraries in Java
Open Source Command Line Interpreters in Java
* Jakarta Commons CLI - The Apache Commons CLI library provides an API for processing command line interfaces. There are three stages to command line processing. They are the definition, parsing and interrogation stages.
* See all Open Source Command Line Interpreters in Java
Open Source Database Connection Pools
* Jakarta DBCP - DBCP is a database connection pool that relies on code in the Jakarta commons-pool package to provide the underlying object pool mechanisms that it utilizes. Applications can use the DBCP component directly or through the existing interface of their container / supporting framework.
* See all Open Source Database Connection Pools
Open Source Crawlers in Java
* Heritrix - Heritrix is the Internet Archive's open-source, extensible, web-scale, archival-quality web crawler project.
* See all Open Source Crawlers in Java
Open Source Database Engines in Java
* Apache Derby - Derby is a Java RDBMS undergoing incubation at Apache Software Foundation. It is a fully functioned standards based JDBC & SQL RDBMS with tables, indexes, views, triggers, sub-queries, procedures, functions, transactions, isolation levels, encryption, etc. Derby is the open sourcing of the IBM Cloudscape technology.
* See all Open Source Database Engines in Java
Open Source EJB Servers
* JBoss - JBoss is advanced middleware with a full J2EE based personality that IT departments look for. But that is not all, the OEM and ISV community embraced JBoss as a highly flexible service oriented architecture on which to build their own products.
* See all Open Source EJB Servers
Open Source ERP & CRM Software
* Apache OFBiz (Apache Open For Business Project) - The Apache Open For Business Project is an open source enterprise automation software project. By open source enterprise automation we mean: Open Source ERP, Open Source CRM, Open Source E-Business / E-Commerce, Open Source SCM, Open Source MRP, Open Source CMMS/EAM, and so on.
* See all Open Source ERP & CRM Software
Open Source Enterprise Service Bus in Java
* Mule - Mule is a light-weight messaging framework. It is a highly distributable object broker that can seamlessly handle interactions with other applications using disparate technologies, transports and protocols. The Mule framework provides a highly scalable environment in which you can deploy your business components. Mule manages all the interactions between components transparently whether they exist in the same VM or over the internet and regardless of the underlying transport used. Mule was designed around the Enterprise Service Bus architecture, which stipulates that different components or applications communicate through a common messaging bus, usually implemented using Jms or some other messaging server. Mule goes a lot further by abstracting Jms and any other transport technology away from the business objects used to receive messages from the bus.
* See all Open Source Enterprise Service Bus in Java
Open Source Eclipse Plugins
* Spring IDE - Spring IDE is a graphical user interface for the configuration files used by the Spring Framework. Spring IDE provides the following features:
* Project nature which supports a list of Spring bean config files and sets of bean config files (aka beans config sets)
* Incremental builder which validates all modified Spring bean config files defined in a Spring project
* View which displays a tree with all Spring projects and their Spring bean config files
* Image decorator which decorates all Spring projects, their bean config files and all Java classes which are used as bean classes
* Graph which shows all beans (and their relationships) defined in a single config file or a config set
* XML editor for Spring beans configuration files
* Extension of Eclipse's search facility to search for beans defined in the BeansCoreModel
* Wizard for creating a new Spring project
* Content contribution to Eclipse's ProjectExplorer with Spring artefacts
* See all Open Source Eclipse Plugins
Open Source Expression Languages in Java
* Jakarta JXPath - JXPath defines a simple interpreter of an expression language called XPath. JXPath applies XPath expressions to graphs of objects of all kinds: JavaBeans, Maps, Servlet contexts, DOM etc, including mixtures thereof.
* See all Open Source Expression Languages in Java
Open Source Financial Software in Java
* JMoney - JMoney is a personal finance manager. It supports multiple accounts in different currencies, double entry banking, income/expense categories, various reports and Quicken file (QIF) exchange. It is built using the Eclipse RCP and can be extended using plug-ins.
* See all Open Source Financial Software in Java
Open Source Forum Software in Java
* JForum - JForum is a powerful and robust discussion board system implemented in Javatm. It provides an attractive interface, an efficient forum engine, an easy to use administrative panel, an advanced permission control system and much more.
* See all Open Source Forum Software in Java
Open Source General Purpose Libraries in Java
* Ostermiller Utils - Libraries for common tasks such as CSV, Base64, Circular Buffers, MD5, and Significant Figures.
* See all Open Source General Purpose Libraries in Java
Open Source Geospacial Software in Java
* deegree - deegree is a Java Framework offering the main building blocks for Spatial Data Infrastructures. Its entire architecture is developed using standards of the Open Geospatial Consortium (OGC) and ISO/TC 211 (ISO Technical Committee 211 -- Geographic Information/Geomatics). deegree encompasses OGC Web Services as well as Clients and security components.
* See all Open Source Geospacial Software in Java
Open Source Groupware Software in Java
* CHEF - The CompreHensive collaborativE Framework (CHEF) initiative has as its goal, the development of a flexible environment for supporting distance learning and collaborative work.
* See all Open Source Groupware Software in Java
Open Source HTML Parsers in Java
* JTidy - JTidy is a Java port of HTML Tidy , a HTML syntax checker and pretty printer. Like its non-Java cousin, JTidy can be used as a tool for cleaning up malformed and faulty HTML. In addition, JTidy provides a DOM interface to the document that is being processed, which effectively makes you able to use JTidy as a DOM parser for real-world HTML.
* See all Open Source HTML Parsers in Java
Open Source IDEs in Java
* Eclipse - Eclipse is a kind of universal tool platform - an open extensible IDE for anything and nothing in particular.
* See all Open Source IDEs in Java
Open Source Installers Generators in Java
* JSmooth - JSmooth is a Java Executable Wrapper that makes a standard Windows executable binary (.exe) from a jar file. It makes java deployment much smoother and user-friendly, as it is able to find a Java VM by itself. When no VM is available, it provides feed-back to the users, and can launch the default web browser to an URL that explains how to download a Java VM. Note: NOT COMPLETELY WRITTEN IN JAVA
* See all Open Source Installers Generators in Java
Open Source Inversion of Control Containers
* Excalibur - Excalibur is an open source software project of The Apache Software Foundation that contains a lightweight, embeddable Inversion of Control container named Fortress that is written in java.
* See all Open Source Inversion of Control Containers
Open Source Issue Tracking Software in Java
* Scarab - The goal of the Scarab project is to build an Artifact tracking system that has the following features:
* A full feature set similar to those found in other Artifact tracking systems: data entry, queries, reports, notifications to interested parties, collaborative accumulation of comments, dependency tracking
* In addition to the standard features, Scarab has fully customizable and unlimited numbers of Modules (your various projects), Artifact types (Defect, Enhancement, Requirement, etc), Attributes (Operating System, Status, Priority, etc), Attribute options (P1, P2, P3) which can all be defined on a per Module basis so that each of your modules is configured for your specific tracking requirements.
* Built using Java Servlet technology for speed, scalability, maintainability, and ease of installation.
* Import/Export ability via XML allowing for easy migration from other systems (e.g. Bugzilla).
* Modular code design that allows manageable modifications of existing and new features over time.
* Fully customizable through a set of administrative pages.
* Easily modified UI look and feel.
* Can be integrated into larger systems by re-implementing key interfaces.
* Is a ready to use issue management system
* See all Open Source Issue Tracking Software in Java
Open Source J2EE Frameworks
* Spring - Spring is a layered Java/J2EE application framework, based on code published in Expert One-on-One J2EE Design and Development
* See all Open Source J2EE Frameworks
Open Source JDBC Drivers
* jTDS - jTDS is an open source 100% pure Java (type 4) JDBC 3.0 driver for Microsoft SQL Server (6.5, 7, 2000 and 2005) and Sybase (10, 11, 12). jTDS is based on the work of the FreeTDS project and is currently the fastest complete JDBC driver for SQL Server and Sybase. Starting with release 0.7.1 jTDS is 100% JDBC 2.1 compatible, supporting forward-only and scrollable/updateable ResultSets, multiple concurrent (completely independent) Statements per Connection and implementing all of the DatabaseMetaData and ResultSetMetaData methods. As of version 0.9 most of the JDBC 3.0 features are also implemented. Quite a few of the commercial JDBC drivers out there are based on jTDS (or FreeTDS), even if they no longer acknowledge this. jTDS has been tested with virtually all of the available JDBC-based database management tools and is the driver of choice for most of these (DataDino and Aqua Data Studio even contain it). jTDS is also becoming a common choice for enterprise-level applications: starting with release 0.8-rc1 jTDS passes the Hibernate test suite, making it the driver of choice for SQL Server.
* See all Open Source JDBC Drivers
Open Source JMS
* OpenJMS - OpenJMS is an open source implementation of Sun Microsystems's Java Message Service API 1.0.2 Specification. Features include:
* Point-to-Point and publish-subscribe messaging models
* Guaranteed delivery of messages
* Synchronous and asynchronous message delivery
* Persistence using JDBC
* Local transactions
* Message filtering using SQL92-like selectors
* Authentication
* Administration GUI
* XML-based configuration files
* In-memory and database garbage collection
* Automatic client disconnection detection
* Applet support
* Integrates with Servlet containers such as Jakarta Tomcat
* Support for RMI, TCP, HTTP and SSL protocol stacks
* Support for large numbers of destinations and subscribers
* See all Open Source JMS
Open Source JMX Tools
* MX4J - MX4J is a project to build an Open Source implementation of the Java(TM) Management Extensions (JMX) and of the JMX Remote API (JSR 160) specifications, and to build tools relating to JMX.
* See all Open Source JMX Tools
Open Source JSP Tag Libraries
* pack:tag - pack:tag is a JSP Taglib that compresses static resources like JavaScript or Cascading Style Sheets. The Taglib caches the resources, once they are compressed, in memory or to file. When caching to memory, the output is additionally gzipped. Compressing-algorithms could be exchanged per resourcetype, and are extendable by usage of the strategy-pattern. Resources can also be combined to reduce requests.
* See all Open Source JSP Tag Libraries
Open Source Job Schedulers in Java
* Quartz - Quartz is an open source job scheduling system that can be integrated with, or used along side virtually any J2EE or J2SE application. Quartz can be used to create simple or complex schedules for executing tens, hundreds, or even tens-of-thousands of jobs; jobs whose tasks are defined as standard Java components or EJBs.
* See all Open Source Job Schedulers in Java
Open Source Localization & Internationalization Tools
* ICU4J - ICU4J is a java libraries providing Unicode and Globalization support for software applications. Here are a few highlights of the services provided by ICU:
* Code Page Conversion: Convert text data to or from Unicode and nearly any other character set or encoding. ICU's conversion tables are based on charset data collected by IBM over the course of many decades, and is the most complete available anywhere.
* Collation: Compare strings according to the conventions and standards of a particular language, region or country. ICU's collation is based on the Unicode Collation Algorithm plus locale-specific comparison rules from the Common Locale Data Repository, a comprehensive source for this sort of data.
* Formatting: Format numbers, dates, times and currency amounts according the conventions of a chosen locale. This includes translating month and day names into the selected language, choosing appropriate abbreviations, ordering fields correctly, etc. Again, ICU uses data from the Common Locale Data Repository.
* Unicode Support: ICU closely tracks the Unicode standard, providing easy access to all of the many Unicode character properties, Unicode Normalization, Case Folding and other fundamental operations as specified by the Unicode Standard.
* Regular Expression: ICU's regular expressions fully support Unicode while providing very competitive performance.
* Bidi: support for handling text containing a mixture of left to right (English) and right to left (Arabic or Hebrew) data.
* Text Boundaries: Locate the positions of words, sentences, paragraphs within a range of text, or identify locations that would be suitable for line wrapping when displaying the text.
* See all Open Source Localization & Internationalization Tools
Open Source Logging Tools in Java
* Log4j - Log4j is a logging tool that allows you to log at runtime without modifying the application binary. The log4j package is designed so that logging statements can remain in shipped code without incurring a heavy performance cost. Logging behavior can be controlled by editing a configuration file, without touching the application binary.
* See all Open Source Logging Tools in Java
Open Source Mail Clients in Java
* Grendel - Grendel is a mail/news reader entirely written in Java. Its goal is to be a true cross-platform application with a feature set that satisfies the poweruser.
* See all Open Source Mail Clients in Java
Open Source Network Clients in Java
* Jakarta Commons HttpClient - HttpClient provides an efficient, up-to-date, and feature-rich package implementing the client side of the most recent HTTP standards and recommendations.
* See all Open Source Network Clients in Java
Open Source Network Servers in Java
* Apache James - The Apache JAMES Project delivers a rich set of open source solutions, written in Java, related to internet mail and news. JAMES is organized into subprojects with JAMES Server and the Mailet API as their core. Apache JAMES is a project of The Apache Software Foundation (ASF) which encourages a collaborative, consensus-based development process under an open software license. The ASF maintains other Java projects which may also be of interest. These are detailed on the ASF Projects page. We recommended that users of JAMES products subscribe to the JAMES users mailing list.
* See all Open Source Network Servers in Java
Open Source Obfuscators in Java
* ProGuard - ProGuard is a free Java class file shrinker and obfuscator. It can detect and remove unused classes, fields, methods, and attributes. It can then rename the remaining classes, fields, and methods using short meaningless names. The resulting jars are smaller and harder to reverse-engineer.
* See all Open Source Obfuscators in Java
Open Source PDF Libraries in Java
* FOP - FOP is an XSL formatter written in Java. It is used in conjunction with an XSLT transformation engine to format XML documents into PDF.
* See all Open Source PDF Libraries in Java
Open Source Parser Generators in Java
* ANTLR - ANother Tool for Language Recognition, (formerly PCCTS) is a language tool that provides a framework for constructing recognizers, compilers, and translators from grammatical descriptions containing Java, C#, or C++ actions. ANTLR provides excellent support for tree construction, tree walking, and translation.
* See all Open Source Parser Generators in Java
Open Source Persistence Frameworks in Java
* Hibernate - Hibernate is a powerful, ultra-high performance object/relational persistence and query service for Java. Hibernate lets you develop persistent objects following common Java idiom - including association, inheritance, polymorphism, composition and the Java collections framework. Extremely fine-grained, richly typed object models are possible. The Hibernate Query Language, designed as a "minimal" object-oriented extension to SQL, provides an elegant bridge between the object and relational worlds. Hibernate is now the most popular ORM solution for Java.
* See all Open Source Persistence Frameworks in Java
Open Source Portals in Java
* Liferay - Liferay is a portal designed to deploy portlets that adhere to the Portlet API (JSR 168). Many useful portlets are bundled with the portal (Mail, Document Library, Calendar, Message Boards, etc)
* See all Open Source Portals in Java
Open Source Profilers in Java
* NetBeans Profiler - NetBeans Profiler is a project to integrate the JFluid profiling technology, which is being developed by Sun, into the NetBeans IDE. The aim of this project is to provide a powerful and flexible profiling solution that is tightly integrated into the IDE workflow. As the size and complexity of Java applications grow, keeping their performance at the required level becomes progressively difficult. That is why we believe profiling should become a natural part of the development work cycle. To achieve that, we would like to make profiling easy-to-use and as unobtrusive as possible - and the JFluid technology that we use, with dynamic bytecode instrumentation at its heart, suits this goal perfectly.
* See all Open Source Profilers in Java
Open Source Project Management Tools in Java
* XPlanner - XPlanner is a web-based project planning and tracking tool for agile development teams
* See all Open Source Project Management Tools in Java
Open Source RSS & RDF Tools in Java
* Jena - Jena is a Java framework for building Semantic Web applications. It provides a programmatic environment for RDF, RDFS and OWL, including a rule-based inference engine.
* See all Open Source RSS & RDF Tools in Java
Open Source Rule Engines in Java
* SweetRules - SweetRules is a uniquely powerful integrated set of tools for semantic web rules and ontologies, revolving around the RuleML (Rule Markup/Modeling Language) emerging standard for semantic web rules, and supporting also the closely related SWRL (Semantic Web Rule Language), along with the OWL standard for semantic web ontologies, which in turn use XML and, optionally, RDF. (SWRL rules are essentially an expressive subset of RuleML rules.) SweetRules supports the powerful Situated Courteous Logic Programs extension of RuleML, including prioritized conflict handling and procedural attachments for actions and tests. SweetRules' capabilities include semantics-preserving translation and interoperability between a variety of rule and ontology languages (including XSB Prolog, Jess production rules, HP Jena-2, and IBM CommonRules), highly scaleable backward and forward inferencing, and merging of rulebases/ontologies. Procedural attachments can even be WSDL Web Services. SweetRules' pluggability and composition capabilities enable new components to be added relatively quickly. Implemented in Java, SweetRules has a compact codebase (~40K lines of code total for several dozen tools). The SweetRules project is an international, multi-institutional effort, originated and coordinated by the SweetRules group at MIT Sloan led by Benjamin Grosof, and its creation was funded largely by the DAML (DARPA Agent Markup Language) research program which co-pioneered the Semantic Web. SWEET ("Semantic WEb Enabling Technology") is an overall set of tools that Benjamin Grosof's group (with collaborators) has been developing since 2001. Other components in it include the SweetDeal e-contracting system approach and prototype, and the SweetPH system for business process ontologies drawn from the Process Handbook. Hundreds of users have already downloaded SweetRules, inspired in part by its well-received demonstrations in detailed presentations at the DAML Principal Investigators Meeting and the International Semantic Web Conference tutorial program.
* See all Open Source Rule Engines in Java
Open Source SQL Clients in Java
* SQuirreL SQL Client - SQuirreL SQL Client is a graphical Java program that will allow you to view the structure of a JDBC compliant database, browse the data in tables, issue SQL commands etc. The minimum version of Java supported is 1.3
* See all Open Source SQL Clients in Java
Open Source Scripting Languages in Java
* Groovy - Groovy is a new agile dynamic language for the JVM combining lots of great features from languages like Python, Ruby and Smalltalk and making them available to the Java developers using a Java-like syntax. Groovy is designed to help you get things done on the Java platform in a quicker, more concise and fun way - bringing the power of Python and Ruby inside the Java platform. Groovy can be used as an alternative compiler to javac to generate standard Java bytecode to be used by any Java project or it can be used dynamically as an alternative language such as for scripting Java objects, templating or writing unit test cases.
* See all Open Source Scripting Languages in Java
Open Source Search Engines in Java
* Lucene - Jakarta Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
* See all Open Source Search Engines in Java
Open Source Security & Cryptography Tools in Java
* Bouncy Castle Crypto - The Bouncy Castle Crypto APIs is a lightweight cryptography API in Java with a provider for the JCE and JCA, a clean room implementation of the JCE 1.2.1, a library for reading and writing encoded ASN.1 objects and generator for:
* Version 1 and Version 3 X.509 certificates and PKCS12 files.
* Version 2 X.509 attribute certificates.
* S/MIME and CMS (PKCS7).
* OCSP (RFC 2560).
* TSP (RFC 3161).
* OpenPGP (RFC 2440). The lightweight API works with everything from the J2ME to the JDK 1.5
* See all Open Source Security & Cryptography Tools in Java
Source Control Tools in Java
* jCVS - JCVS is a CVS client package written entirely in Java. JCVS provides a complete CVS client/server protocol package that allows any Java program to implement the complete suite of CVS operations. JCVS also provides a Swing based client that provides a commercial quality GUI client for CVS. Finally, jCVS provides a Servlet that allows any Servlet enabled web server to present any CVS repository on the internet for browsing and download.
* See all Source Control Tools in Java
Open Source Swing Frameworks & Components
* JGoodies Binding - The JGoodies Binding synchronizes object properties with Swing components. And it helps you represent the state and behavior of a presentation independently of the GUI components used in the interface.
* See all Open Source Swing Frameworks & Components
Open Source Template Engines in Java
* Velocity - Velocity is a Java-based template engine. It permits web page designers to reference methods defined in Java code. Velocity can be used to generate web pages, SQL, PostScript and other output from templates. It can be used either as a standalone utility for generating source code and reports, or as an integrated component of other systems
* See all Open Source Template Engines in Java
Open Source Testing Tools in Java
* JUnit - JUnit is a regression testing framework written by Erich Gamma and Kent Beck. It is used by the developer who implements unit tests in Java.
* See all Open Source Testing Tools in Java
Open Source Text Processing Tools
* Jakarta ORO - The Jakarta-ORO Java classes are a set of text-processing Java classes that provide Perl5 compatible regular expressions, AWK-like regular expressions, glob expressions, and utility classes for performing substitutions, splits, filtering filenames, etc. This library is the successor to the OROMatcher, AwkTools, PerlTools, and TextTools libraries originally from ORO, Inc. Despite little activity in the form of new development initiatives, issue reports, questions, and suggestions are responded to quickly.
* See all Open Source Text Processing Tools
Open Source UML & Modeling in Java
* ArgoUML - ArgoUML is a powerful yet easy-to-use interactive, graphical software design environment that supports the design, development and documentation of object-oriented software applications.
* See all Open Source UML & Modeling in Java
Open Source Validation Frameworks
* Commons Validator - Commons Validator provides the building blocks for both client side validation and server side data validation. It may be used standalone or with a framework like Struts.
* See all Open Source Validation Frameworks
Open Source Web Frameworks in Java
* Struts - The core of the Struts framework is a flexible control layer based on standard technologies like Java Servlets, JavaBeans, ResourceBundles, and XML, as well as various Jakarta Commons packages. Struts encourages application architectures based on the Model 2 approach, a variation of the classic Model-View-Controller (MVC) design paradigm.
* See all Open Source Web Frameworks in Java
Open Source Web Mail Clients in Java
* GatorMail - GatorMail is a servlet-based Webmail built on the Struts framework. It was originally developed to meet the needs of the University of Florida. Efficient interaction with the mail store along with a low support overhead are the goals of the project.
* See all Open Source Web Mail Clients in Java
Open Source Web Servers in Java
* Jigsaw - Jigsaw is W3C's leading-edge Web server platform, providing a sample HTTP 1.1 implementation and a variety of other features on top of an advanced architecture implemented in Java.
* See all Open Source Web Servers in Java
Open Source Web Services Tools in Java
* Axis - Axis is the third generation of Apache SOAP (which began at IBM as "SOAP4J"). It also includes:
* a simple stand-alone server,
* a server which plugs into servlet engines such as Tomcat,
* extensive support for the Web Service Description Language (WSDL),
* emitter tooling that generates Java classes from WSDL.
* some sample programs, and
* a tool for monitoring TCP/IP packets.
* See all Open Source Web Services Tools in Java
Open Source Web Testing Tools in Java
* MaxQ - MaxQ is a free web functional testing tool. It includes an HTTP proxy that records your test script, and a command line utility that can be used to playback tests. The proxy recorder automatically stores variables posted to forms, so you don't have to write that stuff by hand.
* See all Open Source Web Testing Tools in Java
Open Source Wiki Engines in Java
* JSPWiki - A WikiWiki web clone written using JSPs and Servlets
* See all Open Source Wiki Engines in Java
Open Source Workflow Engines in Java
* Apache ODE - Apache ODE (Orchestration Director Engine) executes business processes written following the WS-BPEL standard. It talks to web services, sending and receiving messages, handling data manipulation and error recovery as described by your process definition. It supports both long and short living process executions to orchestrate all the services that are part of your application.
* See all Open Source Workflow Engines in Java
Open Source XML Parsers in Java
* Xerces - The Xerces Java Parser 1.4.4 supports the XML 1.0 recommendation and contains advanced parser functionality, such as support for the W3C's XML Schema recommendation version 1.0, DOM Level 2 version 1.0, and SAX Version 2, in addition to supporting the industry-standard DOM Level 1 and SAX version 1 APIs.
* See all Open Source XML Parsers in Java
Open Source XML UI Toolkits in Java
* Laszlo - Laszlo is an open source platform for the development and delivery of rich Internet applications on the World Wide Web. It is released under the OSI-certified Common Public License. The Laszlo platform consists of the LZX language and the Laszlo Presentation Server. LZX is an XML and JavaScript description language similar in spirit to XUL and XAML. LZX enables a declarative, text-based development process that supports rapid prototyping and software development best practices. The Laszlo Presentation Server (LPS) is a Java servlet that compiles LZX applications into executable binaries for targeted run-time environments. Laszlo currently targets the Flash Player. The LPS compiles LZX applications into SWF bytecode for the Flash Player, serves and caches these compiled applications to any Web browser enabled with Flash 5 or later, and proxies application requests for back-end XML data sources and web services.
Link : http://java-source.net/
Monday, March 10, 2008
PaperClips
Welcome to PaperClips: a simple, light weight, extensible Java printing plug-in for SWT. PaperClips hides the complexity of laying out and rendering documents on the printer, helping you focus on what to print instead of how to print it.
In a nutshell, PaperClips provides an assortment of document "building blocks," which you can tweak and combine to form a custom document. The assembled document is then sent toPaperClips for printing. PaperClips includes support for printing text, images, borders, headers and footers, column layouts and grid layouts, to name a few. It can also be extended with your own printable classes.
With PaperClips you do not have to track cursors, calculate line breaking, fool around with font metrics, or manage system resources--it's all handled internally. And unlike report-generation tools, you are not constrained to a predefined document structure (like report bands). Every document is custom and the layout is up to you.
Requirements:
* Java 1.4 or later.
* SWT 3.2 or later. SWT may be downloaded at http://www.eclipse.org/swt/.
PaperClips can be used as an Eclipse plug-in or as a regular Jar (provided the SWT libraries are on the classpath).
closeclose otherseditpermalinkreferencesjump
News
MatthewHall, 3 November 2007 (created 4 April 2006)
2 November 2007 -- PaperClips 1.0.2 released
* Bugs fixed:
o Clipping problems on Mac OS X.
o PrintPreview.getPageCount() returns 0 before pages are first drawn.
o PrintPreview spits out a blank page on Linux when the window is closed.
o Changed ImageCaptureExample.java to capture JPG since PNG was not fully supported until SWT version 3.3 (PaperClips is developed against 3.2).
o BorderPrint sometimes showed an open bottom border even though the target was completely shown.
o PrintViewer performance improvements when print document is vertically greedy.
* New Features:
o GridPrint.setCellClippingEnabled() controls whether grid cells may be broken across pages. See GridPrintCellClippingExample.java.
o DefaultGridLook.setCellPadding()
o PrintPreview.setHorizontalPageCount() and setVerticalPageCount() controls how many pages are shown on screen.
o Experimental PaperClips.setDebug() API helps troubleshoot documents that won't lay out properly ("Unable to layout on page X" errors).
o BasicGridLookPainter simplifies implementing custom GridLooks.
o StyledTextPrint for mixing text with different font sizes, styles, colors and decorations. Other printable objects such as ImagePrint may be embedded inline with the text.
o TextPrint and StyledTextPrint support underline and strikeout text.
o TextPrint.setWordSplitting() controls whether words may be split between rows. This feature only applies when space is very limited.
o Unified error reporting to PaperClips.error() methods. Custom Print implementations should use these methods to act uniformly with the rest of the library.
* Enhanced print preview snippet (Snippet7):
o Support scrolling with the mouse wheel (horizontally with Shift+Wheel)
o Support zooming with Ctrl+Wheel
8 March 2007 -- PaperClips 1.0.1 released
This is a maintenance release to address printing issues on Mac OS X. Many thanks to the all the Mac users at EclipseCon who graciously provided assistance in fixing this problem.
* Resolved printing problems on Mac OS X.
* Added public accessor APIs for all Print classes.
Download PaperClips 1.0.1
In a nutshell, PaperClips provides an assortment of document "building blocks," which you can tweak and combine to form a custom document. The assembled document is then sent toPaperClips for printing. PaperClips includes support for printing text, images, borders, headers and footers, column layouts and grid layouts, to name a few. It can also be extended with your own printable classes.
With PaperClips you do not have to track cursors, calculate line breaking, fool around with font metrics, or manage system resources--it's all handled internally. And unlike report-generation tools, you are not constrained to a predefined document structure (like report bands). Every document is custom and the layout is up to you.
Requirements:
* Java 1.4 or later.
* SWT 3.2 or later. SWT may be downloaded at http://www.eclipse.org/swt/.
PaperClips can be used as an Eclipse plug-in or as a regular Jar (provided the SWT libraries are on the classpath).
closeclose otherseditpermalinkreferencesjump
News
MatthewHall, 3 November 2007 (created 4 April 2006)
2 November 2007 -- PaperClips 1.0.2 released
* Bugs fixed:
o Clipping problems on Mac OS X.
o PrintPreview.getPageCount() returns 0 before pages are first drawn.
o PrintPreview spits out a blank page on Linux when the window is closed.
o Changed ImageCaptureExample.java to capture JPG since PNG was not fully supported until SWT version 3.3 (PaperClips is developed against 3.2).
o BorderPrint sometimes showed an open bottom border even though the target was completely shown.
o PrintViewer performance improvements when print document is vertically greedy.
* New Features:
o GridPrint.setCellClippingEnabled() controls whether grid cells may be broken across pages. See GridPrintCellClippingExample.java.
o DefaultGridLook.setCellPadding()
o PrintPreview.setHorizontalPageCount() and setVerticalPageCount() controls how many pages are shown on screen.
o Experimental PaperClips.setDebug() API helps troubleshoot documents that won't lay out properly ("Unable to layout on page X" errors).
o BasicGridLookPainter simplifies implementing custom GridLooks.
o StyledTextPrint for mixing text with different font sizes, styles, colors and decorations. Other printable objects such as ImagePrint may be embedded inline with the text.
o TextPrint and StyledTextPrint support underline and strikeout text.
o TextPrint.setWordSplitting() controls whether words may be split between rows. This feature only applies when space is very limited.
o Unified error reporting to PaperClips.error() methods. Custom Print implementations should use these methods to act uniformly with the rest of the library.
* Enhanced print preview snippet (Snippet7):
o Support scrolling with the mouse wheel (horizontally with Shift+Wheel)
o Support zooming with Ctrl+Wheel
8 March 2007 -- PaperClips 1.0.1 released
This is a maintenance release to address printing issues on Mac OS X. Many thanks to the all the Mac users at EclipseCon who graciously provided assistance in fixing this problem.
* Resolved printing problems on Mac OS X.
* Added public accessor APIs for all Print classes.
Download PaperClips 1.0.1
MOZILLA FIREFOX CHEAT SHEET
BASIC
Home:
http://www.mozilla.com/firefox/
Extensions & Themes:
https://addons.mozilla.org/
Support Forum:
http://forums.mozillazine.org/
GENERAL KEYBOARD SHORTCUTS
Add Bookmarks Ctrl + D
Bookmarks Ctrl + B
DOM Inspector Ctrl + Shift + I
Downloads Ctrl + J
Full Screen View F11
Help F1
History Ctrl + H
Page Source Ctrl + U
Print Ctrl + P
Refresh Page F5
Refresh Page & Cache Ctrl + F5
Save Page As Ctrl + S
NAVIGATION KEYBOARD SHORTCUTS
Back Alt + Left Arrow
Down One Line Down
Down One Page PageDown
File Open Ctrl + O
Forward Alt + Right Arrow
Frame Next F6
Frame Previous Shift + F6
Home Page Alt + Home
Jump to Address Bar Ctrl + L
Jump to Search Bar Ctrl + K
Page Bottom End
Page Top Home
Stop Esc
Tab Close Ctrl + W
Tab New Ctrl + T
Tab Next Ctrl + Tab
Tab Previous Ctrl + Shift + Tab
Tab Select Ctrl + [1 - 9]
Up One Line Up
Up One Page PageUp
Window Close Alt + F4
Window New Ctrl + N
TEXT KEYBOARD SHORTCUTS
Copy Ctrl + C
Cut Ctrl + X
Delete Del
Text Size Decrease Ctrl + -
Text Size Increase Ctrl + +
Text Size Default Ctrl + 0
Undo Ctrl + Z
SEARCH KEYBOARD SHORTCUTS
Find Again F3
Find as You Type Link '
Find as You Type Text /
Find in This Page Ctrl + F
Find Previous Shift + F3
MOUSE SHORTCUTS
Back Shift + Scroll Down
Forward Shift + Scroll Up
Open Link in Background Tab Ctrl + Left Click or Middle Click
Open Link in Foreground Tab Ctrl + Shift + Left Click
Open Link in New Window Shift + Left Click
Scroll Line by Line Alt + Scroll
Tab Close Middle Click on Tab
Tab New Double Click on Tab Bar
Text Size Decrease Ctrl + Scroll UP
Text Size Increase Ctrl + Scroll Down
LOCATIONS
Cached Elements
C:\Documents and Settings\[username]\Local Settings\Application Data\Mozilla\Firefox\Profiles\[profilename]\Cache\
Profile Manager
Close Firefox. From the "Start" menu, select "Run", type "firefox.exe -p"
User Profile Folder
C:\Documents and Settings\[username]\Application Data\Mozilla\Firefox\Profiles\xxxxxxxx.default\
Advanced Configuration
Address Bar: about:config
Cache Info
Address Bar: about:cache
Plugin Info
Address Bar: about:plugins
TIPS/TRICKS
Block Popup Windows
Tools -> Options -> Web Features
Customize Toolbars
Right click on a toolbar and chose customize toolbar. To add icons drag and drop them on the toolbar. To subtract icons drag them from the toolbar to the "Customize Toolbar" window.
Desktop Shortcut to Current Page
Drag the icon in the address bar to the desktop
Make Firefox Default Browser
Tools -> Options -> General -> Set Firefox As Default Browser
Manage Cache, Cookies, History and Passwords
Tools -> Options -> Privacy
Set Home Page
Tools -> Options -> General -> Home Page
Tabbed Browsing Options
Tools -> Options -> Advanced -> Tabbed Browsing
Home:
http://www.mozilla.com/firefox/
Extensions & Themes:
https://addons.mozilla.org/
Support Forum:
http://forums.mozillazine.org/
GENERAL KEYBOARD SHORTCUTS
Add Bookmarks Ctrl + D
Bookmarks Ctrl + B
DOM Inspector Ctrl + Shift + I
Downloads Ctrl + J
Full Screen View F11
Help F1
History Ctrl + H
Page Source Ctrl + U
Print Ctrl + P
Refresh Page F5
Refresh Page & Cache Ctrl + F5
Save Page As Ctrl + S
NAVIGATION KEYBOARD SHORTCUTS
Back Alt + Left Arrow
Down One Line Down
Down One Page PageDown
File Open Ctrl + O
Forward Alt + Right Arrow
Frame Next F6
Frame Previous Shift + F6
Home Page Alt + Home
Jump to Address Bar Ctrl + L
Jump to Search Bar Ctrl + K
Page Bottom End
Page Top Home
Stop Esc
Tab Close Ctrl + W
Tab New Ctrl + T
Tab Next Ctrl + Tab
Tab Previous Ctrl + Shift + Tab
Tab Select Ctrl + [1 - 9]
Up One Line Up
Up One Page PageUp
Window Close Alt + F4
Window New Ctrl + N
TEXT KEYBOARD SHORTCUTS
Copy Ctrl + C
Cut Ctrl + X
Delete Del
Text Size Decrease Ctrl + -
Text Size Increase Ctrl + +
Text Size Default Ctrl + 0
Undo Ctrl + Z
SEARCH KEYBOARD SHORTCUTS
Find Again F3
Find as You Type Link '
Find as You Type Text /
Find in This Page Ctrl + F
Find Previous Shift + F3
MOUSE SHORTCUTS
Back Shift + Scroll Down
Forward Shift + Scroll Up
Open Link in Background Tab Ctrl + Left Click or Middle Click
Open Link in Foreground Tab Ctrl + Shift + Left Click
Open Link in New Window Shift + Left Click
Scroll Line by Line Alt + Scroll
Tab Close Middle Click on Tab
Tab New Double Click on Tab Bar
Text Size Decrease Ctrl + Scroll UP
Text Size Increase Ctrl + Scroll Down
LOCATIONS
Cached Elements
C:\Documents and Settings\[username]\Local Settings\Application Data\Mozilla\Firefox\Profiles\[profilename]\Cache\
Profile Manager
Close Firefox. From the "Start" menu, select "Run", type "firefox.exe -p"
User Profile Folder
C:\Documents and Settings\[username]\Application Data\Mozilla\Firefox\Profiles\xxxxxxxx.default\
Advanced Configuration
Address Bar: about:config
Cache Info
Address Bar: about:cache
Plugin Info
Address Bar: about:plugins
TIPS/TRICKS
Block Popup Windows
Tools -> Options -> Web Features
Customize Toolbars
Right click on a toolbar and chose customize toolbar. To add icons drag and drop them on the toolbar. To subtract icons drag them from the toolbar to the "Customize Toolbar" window.
Desktop Shortcut to Current Page
Drag the icon in the address bar to the desktop
Make Firefox Default Browser
Tools -> Options -> General -> Set Firefox As Default Browser
Manage Cache, Cookies, History and Passwords
Tools -> Options -> Privacy
Set Home Page
Tools -> Options -> General -> Home Page
Tabbed Browsing Options
Tools -> Options -> Advanced -> Tabbed Browsing
Wednesday, March 05, 2008
Don't Use Mobile Phone During Storms, Warn Doctors
They describe the case of a 15 year old girl who was witnessed being struck by lightning while using her mobile phone in a large park in London during stormy weather. She was successfully resuscitated, but one year later she suffered complex physical, cognitive, and emotional problems.
If someone is struck by lightning, the high resistance of human skin results in lightning being conducted over the skin without entering the body, explain the authors. This is known as flashover and has a low death rate. Conductive materials such as liquids or metallic objects disrupt the flashover and result in internal injury with greater death rates.
To their knowledge, no similar cases have been reported in the medical literature. They found three cases reported in newspapers in China, Korea, and Malaysia, all resulting in death.
"This rare phenomenon is a public health issue, and education is necessary to highlight the risk of using mobile phones outdoors during stormy weather to prevent future fatal consequences from lightning strike injuries related to mobile phones," say the authors.
"The Australian Lightning Protection Standard recommends that metallic objects, including cordless or mobile phones, should not be used (or carried) outdoors during a thunderstorm," they add. "We could not find any advice from British telecommunication companies."
If someone is struck by lightning, the high resistance of human skin results in lightning being conducted over the skin without entering the body, explain the authors. This is known as flashover and has a low death rate. Conductive materials such as liquids or metallic objects disrupt the flashover and result in internal injury with greater death rates.
To their knowledge, no similar cases have been reported in the medical literature. They found three cases reported in newspapers in China, Korea, and Malaysia, all resulting in death.
"This rare phenomenon is a public health issue, and education is necessary to highlight the risk of using mobile phones outdoors during stormy weather to prevent future fatal consequences from lightning strike injuries related to mobile phones," say the authors.
"The Australian Lightning Protection Standard recommends that metallic objects, including cordless or mobile phones, should not be used (or carried) outdoors during a thunderstorm," they add. "We could not find any advice from British telecommunication companies."
Secrets Of The Masters: Core Java Job Interview Questions
JDJ's Enterprise Editor, Yakov Fain (pictured) writes: If you are planning to hit the job market, you may need to refresh some of the Java basic terms and techniques to prepare yourself for a technical interview. Let me offer you some of the core Java questions that you might expect during the interviews.
For most questions I’ve provided only short answers to encourage further research. I have included only questions for mid (*) and senior level (**) Java developers. These sample questions could also become handy for people who need to interview Java developers (see also the article "Interviewing Enterprise Java Developers").
30 Java Interview Questions
* Q1. How could Java classes direct program messages to the system console, but error messages, say to a file?
A. The class System has a variable out that represents the standard output, and the variable err that represents the standard error device. By default, they both point at the system console. This how the standard output could be re-directed:
Stream st = new Stream(new FileOutputStream("output.txt")); System.setErr(st); System.setOut(st);
* Q2. What's the difference between an interface and an abstract class?
A. An abstract class may contain code in method bodies, which is not allowed in an interface. With abstract classes, you have to inherit your class from it and Java does not allow multiple inheritance. On the other hand, you can implement multiple interfaces in your class.
* Q3. Why would you use a synchronized block vs. synchronized method?
A. Synchronized blocks place locks for shorter periods than synchronized methods.
* Q4. Explain the usage of the keyword transient?
A. This keyword indicates that the value of this member variable does not have to be serialized with the object. When the class will be de-serialized, this variable will be initialized with a default value of its data type (i.e. zero for integers).
* Q5. How can you force garbage collection?
A. You can't force GC, but could request it by calling System.gc(). JVM does not guarantee that GC will be started immediately.
* Q6. How do you know if an explicit object casting is needed?
A. If you assign a superclass object to a variable of a subclass's data type, you need to do explicit casting. For example:
Object a; Customer b; b = (Customer) a;
When you assign a subclass to a variable having a supeclass type, the casting is performed automatically.
* Q7. What's the difference between the methods sleep() and wait()
A. The code sleep(1000); puts thread aside for exactly one second. The code wait(1000), causes a wait of up to one second. A thread could stop waiting earlier if it receives the notify() or notifyAll() call. The method wait() is defined in the class Object and the method sleep() is defined in the class Thread.
* Q8. Can you write a Java class that could be used both as an applet as well as an application?
A. Yes. Add a main() method to the applet.
* Q9. What's the difference between constructors and other methods?
A. Constructors must have the same name as the class and can not return a value. They are only called once while regular methods could be called many times.
* Q10. Can you call one constructor from another if a class has multiple constructors
A. Yes. Use this() syntax.
* Q11. Explain the usage of Java packages.
A. This is a way to organize files when a project consists of multiple modules. It also helps resolve naming conflicts when different packages have classes with the same names. Packages access level also allows you to protect data from being used by the non-authorized classes.
* Q12. If a class is located in a package, what do you need to change in the OS environment to be able to use it?
A. You need to add a directory or a jar file that contains the package directories to the CLASSPATH environment variable. Let's say a class Employee belongs to a package com.xyz.hr; and is located in the file c:\dev\com\xyz\hr\Employee.java. In this case, you'd need to add c:\dev to the variable CLASSPATH. If this class contains the method main(), you could test it from a command prompt window as follows:
c:\>java com.xyz.hr.Employee
* Q13. What's the difference between J2SDK 1.5 and J2SDK 5.0?
A.There's no difference, Sun Microsystems just re-branded this version.
* Q14. What would you use to compare two String variables - the operator == or the method equals()?
A. I'd use the method equals() to compare the values of the Strings and the == to check if two variables point at the same instance of a String object.
* Q15. Does it matter in what order catch statements for FileNotFoundException and IOExceptipon are written?
A. Yes, it does. The FileNoFoundException is inherited from the IOException. Exception's subclasses have to be caught first.
* Q16. Can an inner class declared inside of a method access local variables of this method?
A. It's possible if these variables are final.
* Q17. What can go wrong if you replace && with & in the following code:
String a=null; if (a!=null && a.length()>10) {...}
A. A single ampersand here would lead to a NullPointerException.
* Q18. What's the main difference between a Vector and an ArrayList
A. Java Vector class is internally synchronized and ArrayList is not.
* Q19. When should the method invokeLater()be used?
A. This method is used to ensure that Swing components are updated through the event-dispatching thread.
* Q20. How can a subclass call a method or a constructor defined in a superclass?
A. Use the following syntax: super.myMethod(); To call a constructor of the superclass, just write super(); in the first line of the subclass's constructor.
For most questions I’ve provided only short answers to encourage further research. I have included only questions for mid (*) and senior level (**) Java developers. These sample questions could also become handy for people who need to interview Java developers (see also the article "Interviewing Enterprise Java Developers").
30 Java Interview Questions
* Q1. How could Java classes direct program messages to the system console, but error messages, say to a file?
A. The class System has a variable out that represents the standard output, and the variable err that represents the standard error device. By default, they both point at the system console. This how the standard output could be re-directed:
Stream st = new Stream(new FileOutputStream("output.txt")); System.setErr(st); System.setOut(st);
* Q2. What's the difference between an interface and an abstract class?
A. An abstract class may contain code in method bodies, which is not allowed in an interface. With abstract classes, you have to inherit your class from it and Java does not allow multiple inheritance. On the other hand, you can implement multiple interfaces in your class.
* Q3. Why would you use a synchronized block vs. synchronized method?
A. Synchronized blocks place locks for shorter periods than synchronized methods.
* Q4. Explain the usage of the keyword transient?
A. This keyword indicates that the value of this member variable does not have to be serialized with the object. When the class will be de-serialized, this variable will be initialized with a default value of its data type (i.e. zero for integers).
* Q5. How can you force garbage collection?
A. You can't force GC, but could request it by calling System.gc(). JVM does not guarantee that GC will be started immediately.
* Q6. How do you know if an explicit object casting is needed?
A. If you assign a superclass object to a variable of a subclass's data type, you need to do explicit casting. For example:
Object a; Customer b; b = (Customer) a;
When you assign a subclass to a variable having a supeclass type, the casting is performed automatically.
* Q7. What's the difference between the methods sleep() and wait()
A. The code sleep(1000); puts thread aside for exactly one second. The code wait(1000), causes a wait of up to one second. A thread could stop waiting earlier if it receives the notify() or notifyAll() call. The method wait() is defined in the class Object and the method sleep() is defined in the class Thread.
* Q8. Can you write a Java class that could be used both as an applet as well as an application?
A. Yes. Add a main() method to the applet.
* Q9. What's the difference between constructors and other methods?
A. Constructors must have the same name as the class and can not return a value. They are only called once while regular methods could be called many times.
* Q10. Can you call one constructor from another if a class has multiple constructors
A. Yes. Use this() syntax.
* Q11. Explain the usage of Java packages.
A. This is a way to organize files when a project consists of multiple modules. It also helps resolve naming conflicts when different packages have classes with the same names. Packages access level also allows you to protect data from being used by the non-authorized classes.
* Q12. If a class is located in a package, what do you need to change in the OS environment to be able to use it?
A. You need to add a directory or a jar file that contains the package directories to the CLASSPATH environment variable. Let's say a class Employee belongs to a package com.xyz.hr; and is located in the file c:\dev\com\xyz\hr\Employee.java. In this case, you'd need to add c:\dev to the variable CLASSPATH. If this class contains the method main(), you could test it from a command prompt window as follows:
c:\>java com.xyz.hr.Employee
* Q13. What's the difference between J2SDK 1.5 and J2SDK 5.0?
A.There's no difference, Sun Microsystems just re-branded this version.
* Q14. What would you use to compare two String variables - the operator == or the method equals()?
A. I'd use the method equals() to compare the values of the Strings and the == to check if two variables point at the same instance of a String object.
* Q15. Does it matter in what order catch statements for FileNotFoundException and IOExceptipon are written?
A. Yes, it does. The FileNoFoundException is inherited from the IOException. Exception's subclasses have to be caught first.
* Q16. Can an inner class declared inside of a method access local variables of this method?
A. It's possible if these variables are final.
* Q17. What can go wrong if you replace && with & in the following code:
String a=null; if (a!=null && a.length()>10) {...}
A. A single ampersand here would lead to a NullPointerException.
* Q18. What's the main difference between a Vector and an ArrayList
A. Java Vector class is internally synchronized and ArrayList is not.
* Q19. When should the method invokeLater()be used?
A. This method is used to ensure that Swing components are updated through the event-dispatching thread.
* Q20. How can a subclass call a method or a constructor defined in a superclass?
A. Use the following syntax: super.myMethod(); To call a constructor of the superclass, just write super(); in the first line of the subclass's constructor.
Creating a common lexicon for software development in your organization
While at lunch with a buddy of mine the other day he shared that he came to a startling revelation. He was listening to a presentation on Services Oriented Architecture (SOA) the day before and realized that much of his job was terms definition. Simple things like, what does the word "Enable" mean to you. What is an Enterprise Network Bus?
In software development we often use terms with one another which are poorly defined and have different meanings to different members of the team. We assume that when we say "factory pattern" the person on the other end understands us the same way they understand us when we say "cat." This is, however, rarely the case.
In this article, we'll explore the need for a common lexicon (see the dictionary.com definition for details) for your software development team and look at what you need to do to create it.
The Tower of Babel
"The LORD said, 'If as one people speaking the same language they have begun to do this, then nothing they plan to do will be impossible for them. Come, let us go down and confuse their language so they will not understand each other.'" The Holy Bible, New International Version, Genesis Chapter 11, verses 5-7
When people speak with one language, one understanding of each other, they are able to accomplish almost anything. The more that we are able to speak, hear, and understand each other the less time is wasted on stupid mistakes and misunderstandings.
Most people have had situations where we've given direction to someone and come back only to find that the direction we gave wasn't clear to the recipient. Or at the very least we've taken some direction from someone and when we demonstrated what we had done they indicated they were expecting something different. (This still happens when my wife asks me to do something.)
It's annoying but in software development it's costly. Estimates vary but the general consensus is that over 40 percent of a project's budget may be consumed by rework. If you consider that most of this rework isn't because of poor understanding of how the technology works, but in because of poor communication, you can see a great potential for improvement in the performance of your team by communicating better and reducing rework.
The foundation for creating less rework is in developing a common language that you can use to communicate as clearly as possible. It will never be perfect, but having the same understanding of a word will radically improve your chances of fully understanding what someone else is communicating.
Relearning existing vocabulary
One of the challenges with meeting the call to develop your own lexicon, your own language, with your developers is building common experience and common understanding of the things that you already believe that you know. You may believe that you know what the other person means but in reality you probably believe something slightly different.
Take for instance, when I said "cat" above. You may have thought I was talking about "Fluffy" the white haired Persian cat that you had as a child. Or perhaps you were thinking of the Calico cat you have today. I was, however, actually, referring to one of the Bengal tigers that I recently saw. Should I have pointed out that I was speaking of a "big cat"? Probably, and if I was giving direction I would have. However, even big cat isn't specific. Would I be referring to a leopard, a lion, or a tiger?
The point of all of this is that we all share a vocabulary but we each define the words slightly differently. The trick is to pull the definitions of a group of people together as much as possible so that you can use words and know what they will mean to your team members.
One technique for doing this is finding examples of articles, white papers, etc. that defines the term and expands upon it's meaning. For instance, Services Oriented Architecture is a difficult thing for most people to define. However, you can bring folks to a common understanding by asking or encouraging them to read the same article on SOA as the rest of the team. While everyone may not agree on every specific point about SOA raised in the article it creates a reference point that can be used to anchor a definition that everyone on the team agrees upon.
That anchored definition allows you to define other terms in relationship to it, and to other terms, and helps to strengthen the continuity of understanding between team members. However, even well understood, anchored terms may not be enough.
Creating new vocabulary
Your existing vocabulary is a good start. With seasoned practitioners there's a wide variety of words and phrases that have – or can have – a specific meaning. However, there are times when the existing vocabulary just won't cut it. When you're trying to describe your own techniques, processes, or methodologies, you may find that the existing vocabulary just doesn't cover it.
A former coworker of mine, David Feinberg, has a dream. He wants to get a new word added to the dictionary. It's a great dream, and I wish him luck. Of course, whether he does or doesn't succeed in his goals, he's good at introducing new words into his organization. The beauty of these words is that they mean a specific thing to everyone in the organization – and there is little chance of anyone outside the organization having a different definition.
Although it may seem like having others not know the word would not be a good thing – it can be. It's good because there's a low chance that the word will be misinterpreted. Because there are no other context clues as to the meaning of the word, it's likely that the only definition that the team will develop is the one that is intended.
The most difficult problems to troubleshoot, diagnose, and fix are those which are not clear and repeatable. The same goes with communications. If you can't see that it's a problem, and if it's not a problem all the time, you will probably have a hard time getting people on the same page. A new vocabulary item has the benefit of being understood or not understood, but with a very low probability of being understood incorrectly.
Culture of precision
One of the great benefits that I get out of having different professional editors looking at more than 80 percent of everything that I write is that they have encouraged me to be more specific in my writing. I can't just say things happen – I have to be more specific about what, when, for how long, etc. We all speak in somewhat general terms when we are speaking. It's less formal and we're thinking on our feet, however, the general way that we approach speaking leads to a certain amount of ambiguity and imprecision. The most frequent situation that illuminates the lack of precision is when we ask someone a question via email. We indicate the question but rarely do we actually indicate a deadline for the response. We leave ambiguity in how long the person has to respond to our inquiry.
The impact of a culture of precision in speaking and writing is subtle. It is subtle because you can develop your own lexicon for developers without it; however, it's like a catalyst. It can accelerate the process. By making the team hunger for precision in their communications they will seek out the most precise words they can find to express their ideas. Instead of just being satisfied with the idea that a data entry screen is necessary, they'll begin to explore which of the standard operations they need. Instead of data entry screens you'll get something like. "We need an edit screen for the customer list capable of adding, reading, editing, and disabling a customer. We never delete customers so that isn't necessary."
Perhaps it takes a few more words to communicate like this, perhaps even a minute's worth of time is "wasted" by this precise way of communicating, but that certainly takes less time than coding a delete feature into a screen that will never be used because the business process doesn't allow customers to be deleted.
Culture of refinement
A culture of precision is not only about speaking and writing in precise terms but is also about learning how to hear with precision. In other words, communicating in precise terms also requires that the listener verify the meaning that they attribute to the words that the speaker used. A culture of refinement is one where listeners are encouraged to challenge their understanding of what the speaker said by echoing back the understanding – and not the words. This leads to an automatic refinement of the message which makes it even more precise.
The Humanist approach to psychology is based upon the idea that you tell the person what you just heard. The technique is both validating to the patient and illuminating to the counselor. The patient feels like they're being truly heard and has an opportunity to expand upon the details of the situation or how they feel. The counselor verifies their understanding of the patient and in return understands better.
The basic format is the speaker saying something like "I believe we need a SOA-based approach to this problem." The recipient (or one of the recipients in a group setting) says something like "I understand that you believe Web services are the right way to go with this project." The response doesn't use the same words that the speaker used. It uses a slightly different construction and in this case with a slightly different meaning. The result should be the speaker responding with "Yes, but I believe we need to address queuing and the transactional nature of what we're doing. I also believe that we have to focus on maintaining loose coupling." This interchange has illuminated that the speaker believes that queuing (asynchronous operation), transactional processing, and loose coupling are important components of the solution. Without this reflection of meaning back to the speaker this information would have never been shared.
This culture of refinement, where everyone is trying to refine their understanding of what is being said can be a bit overwhelming at first as it initially increases communications, however, it has the potential to substantially reduce rework.
The world at large
One of the challenges that occur when you create your own lexicon for communication is that the world creeps in around you. You're overwhelmed by messages from the rest of the world which may have a different definition of your terms than the group defines. That's one of the reasons why it's important to find your own vocabulary so that you don't have to battle a different meaning in the world at large. Prefixing terms with 'OurCo' such as in OurCo-SOA can help to keep the distinction even when the world has a slightly different or less refined meaning.
Ultimately there is one major caution with your lexicon. That is not to make it conflict with the meaning of the world at large. So you wouldn't, for instance, want to define a Web service as a Web site that users use on top of existing mainframe applications. The definition would be substantially inconsistent with the definition used by the rest of the world and would simply lead to problems of misunderstandings when you try to bring in new people, communicate with your peers, or even get consultants "up to speed" as they come in.
The best way to view your lexicon is a dialect. Something that resembles the way the outside world communicates, but has special and unique meaning to the team – a meaning that makes it easier and more productive to communicate.
The mind
You may not need to create a whole new language or learn some obscure language like Klingon but you should consider how you communicate with your team and how you can create your own lexicon for communicating back and forth with one another.
Learn to anchor your key terms and apply your own definitions to new words to form a stronger bond between the meaning behind the communication in the mind of the speaker and the meaning behind the communication in the mind of the listener.
In software development we often use terms with one another which are poorly defined and have different meanings to different members of the team. We assume that when we say "factory pattern" the person on the other end understands us the same way they understand us when we say "cat." This is, however, rarely the case.
In this article, we'll explore the need for a common lexicon (see the dictionary.com definition for details) for your software development team and look at what you need to do to create it.
The Tower of Babel
"The LORD said, 'If as one people speaking the same language they have begun to do this, then nothing they plan to do will be impossible for them. Come, let us go down and confuse their language so they will not understand each other.'" The Holy Bible, New International Version, Genesis Chapter 11, verses 5-7
When people speak with one language, one understanding of each other, they are able to accomplish almost anything. The more that we are able to speak, hear, and understand each other the less time is wasted on stupid mistakes and misunderstandings.
Most people have had situations where we've given direction to someone and come back only to find that the direction we gave wasn't clear to the recipient. Or at the very least we've taken some direction from someone and when we demonstrated what we had done they indicated they were expecting something different. (This still happens when my wife asks me to do something.)
It's annoying but in software development it's costly. Estimates vary but the general consensus is that over 40 percent of a project's budget may be consumed by rework. If you consider that most of this rework isn't because of poor understanding of how the technology works, but in because of poor communication, you can see a great potential for improvement in the performance of your team by communicating better and reducing rework.
The foundation for creating less rework is in developing a common language that you can use to communicate as clearly as possible. It will never be perfect, but having the same understanding of a word will radically improve your chances of fully understanding what someone else is communicating.
Relearning existing vocabulary
One of the challenges with meeting the call to develop your own lexicon, your own language, with your developers is building common experience and common understanding of the things that you already believe that you know. You may believe that you know what the other person means but in reality you probably believe something slightly different.
Take for instance, when I said "cat" above. You may have thought I was talking about "Fluffy" the white haired Persian cat that you had as a child. Or perhaps you were thinking of the Calico cat you have today. I was, however, actually, referring to one of the Bengal tigers that I recently saw. Should I have pointed out that I was speaking of a "big cat"? Probably, and if I was giving direction I would have. However, even big cat isn't specific. Would I be referring to a leopard, a lion, or a tiger?
The point of all of this is that we all share a vocabulary but we each define the words slightly differently. The trick is to pull the definitions of a group of people together as much as possible so that you can use words and know what they will mean to your team members.
One technique for doing this is finding examples of articles, white papers, etc. that defines the term and expands upon it's meaning. For instance, Services Oriented Architecture is a difficult thing for most people to define. However, you can bring folks to a common understanding by asking or encouraging them to read the same article on SOA as the rest of the team. While everyone may not agree on every specific point about SOA raised in the article it creates a reference point that can be used to anchor a definition that everyone on the team agrees upon.
That anchored definition allows you to define other terms in relationship to it, and to other terms, and helps to strengthen the continuity of understanding between team members. However, even well understood, anchored terms may not be enough.
Creating new vocabulary
Your existing vocabulary is a good start. With seasoned practitioners there's a wide variety of words and phrases that have – or can have – a specific meaning. However, there are times when the existing vocabulary just won't cut it. When you're trying to describe your own techniques, processes, or methodologies, you may find that the existing vocabulary just doesn't cover it.
A former coworker of mine, David Feinberg, has a dream. He wants to get a new word added to the dictionary. It's a great dream, and I wish him luck. Of course, whether he does or doesn't succeed in his goals, he's good at introducing new words into his organization. The beauty of these words is that they mean a specific thing to everyone in the organization – and there is little chance of anyone outside the organization having a different definition.
Although it may seem like having others not know the word would not be a good thing – it can be. It's good because there's a low chance that the word will be misinterpreted. Because there are no other context clues as to the meaning of the word, it's likely that the only definition that the team will develop is the one that is intended.
The most difficult problems to troubleshoot, diagnose, and fix are those which are not clear and repeatable. The same goes with communications. If you can't see that it's a problem, and if it's not a problem all the time, you will probably have a hard time getting people on the same page. A new vocabulary item has the benefit of being understood or not understood, but with a very low probability of being understood incorrectly.
Culture of precision
One of the great benefits that I get out of having different professional editors looking at more than 80 percent of everything that I write is that they have encouraged me to be more specific in my writing. I can't just say things happen – I have to be more specific about what, when, for how long, etc. We all speak in somewhat general terms when we are speaking. It's less formal and we're thinking on our feet, however, the general way that we approach speaking leads to a certain amount of ambiguity and imprecision. The most frequent situation that illuminates the lack of precision is when we ask someone a question via email. We indicate the question but rarely do we actually indicate a deadline for the response. We leave ambiguity in how long the person has to respond to our inquiry.
The impact of a culture of precision in speaking and writing is subtle. It is subtle because you can develop your own lexicon for developers without it; however, it's like a catalyst. It can accelerate the process. By making the team hunger for precision in their communications they will seek out the most precise words they can find to express their ideas. Instead of just being satisfied with the idea that a data entry screen is necessary, they'll begin to explore which of the standard operations they need. Instead of data entry screens you'll get something like. "We need an edit screen for the customer list capable of adding, reading, editing, and disabling a customer. We never delete customers so that isn't necessary."
Perhaps it takes a few more words to communicate like this, perhaps even a minute's worth of time is "wasted" by this precise way of communicating, but that certainly takes less time than coding a delete feature into a screen that will never be used because the business process doesn't allow customers to be deleted.
Culture of refinement
A culture of precision is not only about speaking and writing in precise terms but is also about learning how to hear with precision. In other words, communicating in precise terms also requires that the listener verify the meaning that they attribute to the words that the speaker used. A culture of refinement is one where listeners are encouraged to challenge their understanding of what the speaker said by echoing back the understanding – and not the words. This leads to an automatic refinement of the message which makes it even more precise.
The Humanist approach to psychology is based upon the idea that you tell the person what you just heard. The technique is both validating to the patient and illuminating to the counselor. The patient feels like they're being truly heard and has an opportunity to expand upon the details of the situation or how they feel. The counselor verifies their understanding of the patient and in return understands better.
The basic format is the speaker saying something like "I believe we need a SOA-based approach to this problem." The recipient (or one of the recipients in a group setting) says something like "I understand that you believe Web services are the right way to go with this project." The response doesn't use the same words that the speaker used. It uses a slightly different construction and in this case with a slightly different meaning. The result should be the speaker responding with "Yes, but I believe we need to address queuing and the transactional nature of what we're doing. I also believe that we have to focus on maintaining loose coupling." This interchange has illuminated that the speaker believes that queuing (asynchronous operation), transactional processing, and loose coupling are important components of the solution. Without this reflection of meaning back to the speaker this information would have never been shared.
This culture of refinement, where everyone is trying to refine their understanding of what is being said can be a bit overwhelming at first as it initially increases communications, however, it has the potential to substantially reduce rework.
The world at large
One of the challenges that occur when you create your own lexicon for communication is that the world creeps in around you. You're overwhelmed by messages from the rest of the world which may have a different definition of your terms than the group defines. That's one of the reasons why it's important to find your own vocabulary so that you don't have to battle a different meaning in the world at large. Prefixing terms with 'OurCo' such as in OurCo-SOA can help to keep the distinction even when the world has a slightly different or less refined meaning.
Ultimately there is one major caution with your lexicon. That is not to make it conflict with the meaning of the world at large. So you wouldn't, for instance, want to define a Web service as a Web site that users use on top of existing mainframe applications. The definition would be substantially inconsistent with the definition used by the rest of the world and would simply lead to problems of misunderstandings when you try to bring in new people, communicate with your peers, or even get consultants "up to speed" as they come in.
The best way to view your lexicon is a dialect. Something that resembles the way the outside world communicates, but has special and unique meaning to the team – a meaning that makes it easier and more productive to communicate.
The mind
You may not need to create a whole new language or learn some obscure language like Klingon but you should consider how you communicate with your team and how you can create your own lexicon for communicating back and forth with one another.
Learn to anchor your key terms and apply your own definitions to new words to form a stronger bond between the meaning behind the communication in the mind of the speaker and the meaning behind the communication in the mind of the listener.
Ten things every Java developer should know about UNIX
One of the great things about Java is how multi-platform it really is. While cross platform glitches do occur, they are not really all that common. But since the law of unintended consequences is all pervasive, we now have the common sight of teams of developers building Java programs meant to run on Unix boxes on Windows.Developing code meant for Unix on Windows does work reasonably well. The trouble is, many those coders slaving away in front of XP have a very limited understanding of their target platform. If that describes you, this following list is meant for you. Without further ado, here are the ten things you really need to know about Unix, in reverse David Letterman order:
10) You need to be special to use some ports
On Unix machines, programs run by ordinary mortals cannot use network ports less than 1024. Only the special root user can use these ports. If you do decide that you need to run your server as root, be very careful since a program running as root is all powerful on a Unix machine.
9) There is no magic file locking
Windows has this magic file locking mechanism that prevents people from removing a file while it is open. Thus, on a Windows box the call to delete() in the following code is pretty much sure to fail:InputStream is = new FileInputStream(”foo.txt”);(new File(”foo.txt”)).delete();int ch;while( (ch = is.read()) > 0 )System.out.println( “char: ” + (char)ch );is.close();The delete will fail because someone (our program in fact) has the file open. After we get done printing out its contents, foo.txt will still be there. The kicker is, the delete() will work just fine on any Unix box. Under Unix, the call to delete() will delete the entry for foo.txt out from the file system, but since someone (our program) still has the file open, the bytes will live on, to be read and printed out. Only when we close the stream will the contents of foo.txt follow its name into oblivion.In exactly the same way, on a Unix box, someone can delete a program’s current directory right out from underneath it.
8 ) Sometimes there is no GUI
People who are used to Windows are sometimes surprised to find their programs running on a Unix box that has no GUI at all. None. Zilch. Nada. In Unix, the GUI is an add on component and it is completely optional. The machine will run fine without it and servers commonly do. Be very careful making calls to those handy java.awt methods — some of them will fail on a machine with no GUI.While you are at it, you may want to rethink what you are writing out with System.out. Many severs not only lack a GUI, they are completely headless: no keyboard, no mouse, no screen. If you are deploying into this kind of environment, the log file is your friend, because your program’s cries for help are unlikely to be heard anywhere else.
7) In Unix, there is no registry……
but if there was, it would be a plain text file. Unix systems have no central place like the Windows registry for storing configuration information. Instead, Unix configuration is spread over a fair number of different files. Many of these files live in a directory called /etc : the list of users is in a file called /etc/passwd, while the name of the machine is typically found in /etc/host.I guess if you are a Windows user that is the bad news. Here is the good news: most, if not all of the configuration files are plain text files. You can look at them with any old text editor. A further bit of good news is that all modern Unix like systems come with GUIs to edit the configuration files.
6) Forward slashes are your friend
This one is really more about Java on Windows than it is about Unix, but useful anyway. Just about everyone knows that Unix uses forward slashes to separate the bits of a path: /etc/passwd, while Windows uses backslashes: c:\Program Files\Windows. What a disturbing number of folks don’t realize is that forward slashes work just fine on in Java on Windows too. On a Windows box, Java is smart enough to translate /a/b/c/foo.txt to something like C:\a\b\c\foo.txt.Should you rely on this for production? No. If you are really coding cross platform Java, you need know about File.pathSeparator and the various File constructors. But if you are coding stuff that is only meant for Unix, and you just want to test it on your windows box, knowing that the forward slashes work in both places can save a lot of agony.
5) Our services are just programs
In Windows, system services are special programs, written to a particular service API. On Unix, services are provided by pretty ordinary programs that do service like things.Typically, a Unix service consists of the useful program and a script which starts the program in the background when the system starts up and may shut it down again when the system is halting. Many Unix systems keep these scripts in the /etc/init.d directory.
4) Environment variables are hard to change
Windows programmers sometimes cook up little batch files that set the environment variables they want. Perhaps you need to roll back to an old version of Java and Ant. You might write a batch file that looks something like:set JAVA_HOME=C:\java1.4.1_05set ANT_HOME=C:\apache-ant-1.6.1They can then run the batch file:c:\> setenv.batand have the environment that you need. If you try to translate this directly into Unix-land, you get a script that looks not too different:#!/bin/shJAVA_HOME=/usr/java1.4.1_05export JAVA_HOMEANT_HOME=/usr/apache-ant-1.6.1export ANT_HOMESo you try out your new script…$ setenv.sh…and it does nothing. The trouble is that the Unix shell runs scripts by creating a copy of itself and running the script in the new shell. This new shell will read in the script, set all the environment variables and then exit, leaving the original shell and its environment unchanged. I hate when that happens. Changing directories works pretty much the same way: if you do a cd in an ordinary shell script, it will change the directory for that second shell, which may or may not be what you want.If what you want is to change things in your current shell, you need to have the current shell read in the script directly, without starting a new shell to do the job. You can do this with by using the dot command:. setenv.shLife will be good as your environment variables change.I should mention that there are several different shells available in Unix. Which one you use is mostly a matter of taste, either yours or the person who set up your account. The commands above will work with many of the common Unix shells, but if you happen to be running the C shell (note the pun), then your little script will need to look something like:setenv JAVA_HOME /usr/java1.4.1_05setenv ANT_HOME /usr/apache-ant-1.6.1You also need a different command to read the script in:source setenv.csh
3) We don’t like spaces in our file names
Okay, this one probably has more to do with Unix users and sys admins than the OS itself, but the fact is, we don’t like spaces in our paths. Oh it is perfectly possibly to have spaces in Unix file names. In fact you can put darn near anything in a Unix file name: /tmp/:a,*b%c is actually the name of a directory on the system that I am using to write this.But can and should are two different things. Unix users spend much of their time using the command line and Unix command line utilities are not crazy about paths with stars, question marks and especially spaces. The Unix guy can always find a way, but if you insist on putting strange characters like spaces in your file names, you are just finding a way to annoy your local Unix guy.
2) There is no carriage to return
If I had just one magic lighting bolt to hurl at one person, I think I would pick the guy who decided to use different line terminating characters on the two major OS’s. I suspect we would have hyper intelligent computers by now were it not for all the time wasted trying to figure out why my file looks funny on your OS.In a plain text file, Windows typically uses a carriage return followed by a newline character to mark the end of a line. Unix dispenses with the carriage return and makes due with the single newline character. Although the tools are getting better, Unix style files may show up as one long line in Windows — not a single carriage return/newline pair in that file, must be a single line. Likewise, Windows style files will sometimes show up on Unix with garbage characters at the end of a line — that extra carriage return is meaningless under the Unix convention.This doesn’t matter much for Java files — it’s all white space to the Java compiler. But some native Unix programs care passionately about those funny characters at the end of a line. In particular if you use a Windows based tool to edit a Unix script and your tool adds carriage returns to the script file, you have screwed it up. The script will no longer run. Worse, since many Unix editors do now handle the carriage returns, you could look at the broken script and see nothing wrong.
1) You need a Linux box
If you are doing significant development for Unix, you owe it to yourself and your customers to know something about Unix. If all else fails, get yourself an old PC and some of that free Linux. Or get yourself one of the many bootable Linux-on-a-CD distributions and try it out on any machine. Java is nearly platform independent, but not quite. It is up to you to make up the difference.
10) You need to be special to use some ports
On Unix machines, programs run by ordinary mortals cannot use network ports less than 1024. Only the special root user can use these ports. If you do decide that you need to run your server as root, be very careful since a program running as root is all powerful on a Unix machine.
9) There is no magic file locking
Windows has this magic file locking mechanism that prevents people from removing a file while it is open. Thus, on a Windows box the call to delete() in the following code is pretty much sure to fail:InputStream is = new FileInputStream(”foo.txt”);(new File(”foo.txt”)).delete();int ch;while( (ch = is.read()) > 0 )System.out.println( “char: ” + (char)ch );is.close();The delete will fail because someone (our program in fact) has the file open. After we get done printing out its contents, foo.txt will still be there. The kicker is, the delete() will work just fine on any Unix box. Under Unix, the call to delete() will delete the entry for foo.txt out from the file system, but since someone (our program) still has the file open, the bytes will live on, to be read and printed out. Only when we close the stream will the contents of foo.txt follow its name into oblivion.In exactly the same way, on a Unix box, someone can delete a program’s current directory right out from underneath it.
8 ) Sometimes there is no GUI
People who are used to Windows are sometimes surprised to find their programs running on a Unix box that has no GUI at all. None. Zilch. Nada. In Unix, the GUI is an add on component and it is completely optional. The machine will run fine without it and servers commonly do. Be very careful making calls to those handy java.awt methods — some of them will fail on a machine with no GUI.While you are at it, you may want to rethink what you are writing out with System.out. Many severs not only lack a GUI, they are completely headless: no keyboard, no mouse, no screen. If you are deploying into this kind of environment, the log file is your friend, because your program’s cries for help are unlikely to be heard anywhere else.
7) In Unix, there is no registry……
but if there was, it would be a plain text file. Unix systems have no central place like the Windows registry for storing configuration information. Instead, Unix configuration is spread over a fair number of different files. Many of these files live in a directory called /etc : the list of users is in a file called /etc/passwd, while the name of the machine is typically found in /etc/host.I guess if you are a Windows user that is the bad news. Here is the good news: most, if not all of the configuration files are plain text files. You can look at them with any old text editor. A further bit of good news is that all modern Unix like systems come with GUIs to edit the configuration files.
6) Forward slashes are your friend
This one is really more about Java on Windows than it is about Unix, but useful anyway. Just about everyone knows that Unix uses forward slashes to separate the bits of a path: /etc/passwd, while Windows uses backslashes: c:\Program Files\Windows. What a disturbing number of folks don’t realize is that forward slashes work just fine on in Java on Windows too. On a Windows box, Java is smart enough to translate /a/b/c/foo.txt to something like C:\a\b\c\foo.txt.Should you rely on this for production? No. If you are really coding cross platform Java, you need know about File.pathSeparator and the various File constructors. But if you are coding stuff that is only meant for Unix, and you just want to test it on your windows box, knowing that the forward slashes work in both places can save a lot of agony.
5) Our services are just programs
In Windows, system services are special programs, written to a particular service API. On Unix, services are provided by pretty ordinary programs that do service like things.Typically, a Unix service consists of the useful program and a script which starts the program in the background when the system starts up and may shut it down again when the system is halting. Many Unix systems keep these scripts in the /etc/init.d directory.
4) Environment variables are hard to change
Windows programmers sometimes cook up little batch files that set the environment variables they want. Perhaps you need to roll back to an old version of Java and Ant. You might write a batch file that looks something like:set JAVA_HOME=C:\java1.4.1_05set ANT_HOME=C:\apache-ant-1.6.1They can then run the batch file:c:\> setenv.batand have the environment that you need. If you try to translate this directly into Unix-land, you get a script that looks not too different:#!/bin/shJAVA_HOME=/usr/java1.4.1_05export JAVA_HOMEANT_HOME=/usr/apache-ant-1.6.1export ANT_HOMESo you try out your new script…$ setenv.sh…and it does nothing. The trouble is that the Unix shell runs scripts by creating a copy of itself and running the script in the new shell. This new shell will read in the script, set all the environment variables and then exit, leaving the original shell and its environment unchanged. I hate when that happens. Changing directories works pretty much the same way: if you do a cd in an ordinary shell script, it will change the directory for that second shell, which may or may not be what you want.If what you want is to change things in your current shell, you need to have the current shell read in the script directly, without starting a new shell to do the job. You can do this with by using the dot command:. setenv.shLife will be good as your environment variables change.I should mention that there are several different shells available in Unix. Which one you use is mostly a matter of taste, either yours or the person who set up your account. The commands above will work with many of the common Unix shells, but if you happen to be running the C shell (note the pun), then your little script will need to look something like:setenv JAVA_HOME /usr/java1.4.1_05setenv ANT_HOME /usr/apache-ant-1.6.1You also need a different command to read the script in:source setenv.csh
3) We don’t like spaces in our file names
Okay, this one probably has more to do with Unix users and sys admins than the OS itself, but the fact is, we don’t like spaces in our paths. Oh it is perfectly possibly to have spaces in Unix file names. In fact you can put darn near anything in a Unix file name: /tmp/:a,*b%c is actually the name of a directory on the system that I am using to write this.But can and should are two different things. Unix users spend much of their time using the command line and Unix command line utilities are not crazy about paths with stars, question marks and especially spaces. The Unix guy can always find a way, but if you insist on putting strange characters like spaces in your file names, you are just finding a way to annoy your local Unix guy.
2) There is no carriage to return
If I had just one magic lighting bolt to hurl at one person, I think I would pick the guy who decided to use different line terminating characters on the two major OS’s. I suspect we would have hyper intelligent computers by now were it not for all the time wasted trying to figure out why my file looks funny on your OS.In a plain text file, Windows typically uses a carriage return followed by a newline character to mark the end of a line. Unix dispenses with the carriage return and makes due with the single newline character. Although the tools are getting better, Unix style files may show up as one long line in Windows — not a single carriage return/newline pair in that file, must be a single line. Likewise, Windows style files will sometimes show up on Unix with garbage characters at the end of a line — that extra carriage return is meaningless under the Unix convention.This doesn’t matter much for Java files — it’s all white space to the Java compiler. But some native Unix programs care passionately about those funny characters at the end of a line. In particular if you use a Windows based tool to edit a Unix script and your tool adds carriage returns to the script file, you have screwed it up. The script will no longer run. Worse, since many Unix editors do now handle the carriage returns, you could look at the broken script and see nothing wrong.
1) You need a Linux box
If you are doing significant development for Unix, you owe it to yourself and your customers to know something about Unix. If all else fails, get yourself an old PC and some of that free Linux. Or get yourself one of the many bootable Linux-on-a-CD distributions and try it out on any machine. Java is nearly platform independent, but not quite. It is up to you to make up the difference.
Friday, February 29, 2008
Open Source Java Reporting with JasperReports and iReport
asperReports, a powerful, flexible open-source reporting engine, is easy to integrate into Java enterprise applications, but it lacks an integrated visual report editor. So, if you want to use JasperReports directly, you need to manipulate its XML report structure—a relatively technical activity with a high learning curve, to say the least.
In fact, writing a full JasperReport from scratch using only the XML format is a long, painful, and unrewarding task.
Luckily, some available alternatives are much easier. The first and foremost of which is to use a visual editor to design, compile, and test your reports.
One of the most useful visual editors you can use is iReport. This article demonstrates how to use iReport to leverage the full power of JasperReports without getting entangled in complexities of the JasperReports native XML format.
Getting Started
The first thing to do is download and install iReport. It is a Java application, so you will need a JDK on your machine (JDK 1.4 or higher). This tutorial uses JDK 1.5.0:
Download iReport from ireport.sourceforge.net.
Decompress the iReport archive.
Run the startup script (bin\startup.bat or ./bin/startup.sh).
The iReport download comes with its own JasperReports package (the latest version to date, 0.5.1, supports the recently released JasperReports 1.0.1).
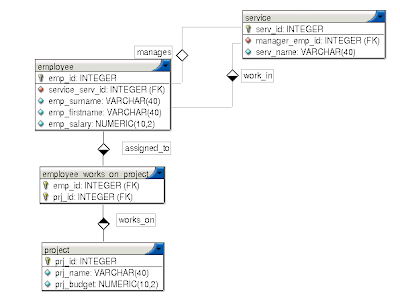
Figure 1. The Tutorial's Employee Database Schema
Once you have iReport running, you can start designing your reports!
The Example Database
This tutorial uses a very simple database (see Figure 1) for demonstration. To follow along step-by-step, either download the scripts for setting up this database with MySQL and set it up on your machine, or use a similar database and translate the techniques to your situation.
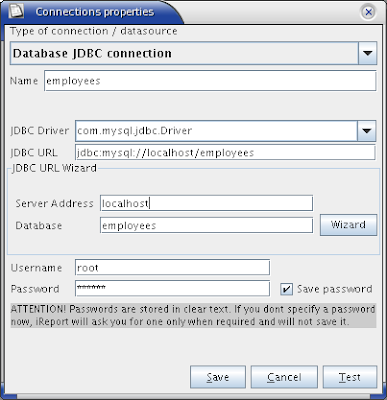
Figure 2. Adding a New Database Connection
Adding a New Database Connection
First, add a new connection to your database. Use the "Datasource -> Connections/Datasources" menu to set up a new database connection (see Figure 2). If you chose the JDBC driver in the list (the example chooses MySQL), enter the server address and the database name, and then click on the 'Wizard' button. iReport should provide you with a correct JDBC URL for your particular database.
Now that you have a datasource, it's time to do something with it.
In fact, writing a full JasperReport from scratch using only the XML format is a long, painful, and unrewarding task.
Luckily, some available alternatives are much easier. The first and foremost of which is to use a visual editor to design, compile, and test your reports.
One of the most useful visual editors you can use is iReport. This article demonstrates how to use iReport to leverage the full power of JasperReports without getting entangled in complexities of the JasperReports native XML format.
Getting Started
The first thing to do is download and install iReport. It is a Java application, so you will need a JDK on your machine (JDK 1.4 or higher). This tutorial uses JDK 1.5.0:
Download iReport from ireport.sourceforge.net.
Decompress the iReport archive.
Run the startup script (bin\startup.bat or ./bin/startup.sh).
The iReport download comes with its own JasperReports package (the latest version to date, 0.5.1, supports the recently released JasperReports 1.0.1).

Figure 1. The Tutorial's Employee Database Schema
Once you have iReport running, you can start designing your reports!
The Example Database
This tutorial uses a very simple database (see Figure 1) for demonstration. To follow along step-by-step, either download the scripts for setting up this database with MySQL and set it up on your machine, or use a similar database and translate the techniques to your situation.

Figure 2. Adding a New Database Connection
Adding a New Database Connection
First, add a new connection to your database. Use the "Datasource -> Connections/Datasources" menu to set up a new database connection (see Figure 2). If you chose the JDBC driver in the list (the example chooses MySQL), enter the server address and the database name, and then click on the 'Wizard' button. iReport should provide you with a correct JDBC URL for your particular database.
Now that you have a datasource, it's time to do something with it.
Generating Huge reports in JasperReports
There are certain things to care while implementing the Jasper Reports for huge dataset to handle the memory efficiently, so that the appliacation does not go out of memory.
They are:
1) Pagination of the data and use of JRDataSource,
2) Viruatization of the report.
When there is a huge dataset, it is not a good idea to retrieve all the data at one time.The application will hog up the memory and you're application will go out of memory even before coming to the jasper report engine to fill up the data.To avoid that, the service layer/Db layer should return the data in pages and you gather the data in chunks and return the records in the chunks using JRDataSource interface, when the records are over in the current chunk, get the next chunk untilall the chunks gets over.When I meant JRDataSource, do not go for the Collection datasources, you implement the JRDataSource interface and provide the data through next() and getFieldValue()To provide an example, I just took the "virtualizer" example from the jasperReports sampleand modified a bit to demonstrate for this article.To know how to implement the JRDataSource, Have a look at the inner class "InnerDS" in the example.
Even after returning the data in chunks, finally the report has to be a single file.Jasper engine build the JasperPrint object for this. To avoid the piling up of memory at this stage, JasperReports provided a really cool feature called Virtualizer. Virtualizer basically serializes and writes the pages into file system to avoid the out of memory condition. There are 3 types of Virtualizer out there as of now. They are JRFileVirtualizer, JRSwapFileVirtualizer, and JRGzipVirtualizer.JRFileVirtualizer is a really simple virtualizer, where you need to mention the number of pages to keep in memory and the directory in which the Jasper Engine can swap the excess pages into files. Disadvantage with this Virtualizer is file handling overhead. This Virtualizer creates so many files during the process of virtualization and finally produces the required report file from those files.If the dataset is not that large, then you can go far JRFileVirtualizer.The second Virtualizer is JRSwapFileVirtualizer, which overcomes the disadvantage of JRFileVirtualizer. JRSwapFileVirtualizer creates only one swap file,which can be extended based on the size you specify. You have to specify the directory to swap, initial file size in number of blocks and the extension size for the JRSwapFile. Then while creating the JRSwapFileVirtualizer, provide the JRSwapFile as a parameter, and the number of pages to keep in memory. This Virtualizer is the best fit for the huge dataset.The Third Virtualizer is a special virtualizer which does not write the data into files, instead it compresses the jasper print object using the Gzip algorithm and reduces the memory consumption in the heap memory.The Ultimate Guide of JasperReports says that JRGzipVirtualizer can reduce the memory consumption by 1/10th. If you are dataset is not that big for sure and if you want to avoid the file I/O, you can go for JRGzipVirtualizer.
Check the sample to know more about the coding part. To keep it simple, I have reused the "virtualizer" sample and added the JRDataSource implementation with paging.I ran the sample that I have attached here for four scenarios. To tighten the limits to get the real effects, I ran the application with 10 MB as the max heap size (-Xmx10M).
1a) No Virtualizer, which ended up in out of memory with 10MB max heap size limit.
export:
[java] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
[java] Java Result: 1
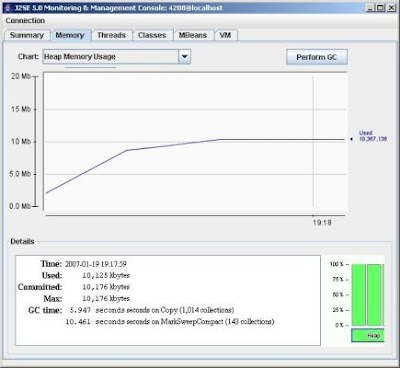
1b) No Virtualizer with default heap size limit (64M)
export2:
[java] null
[java] Filling time : 44547
[java] PDF creation time : 22109
[java] XML creation time : 10157
[java] HTML creation time : 12281
[java] CSV creation time : 2078
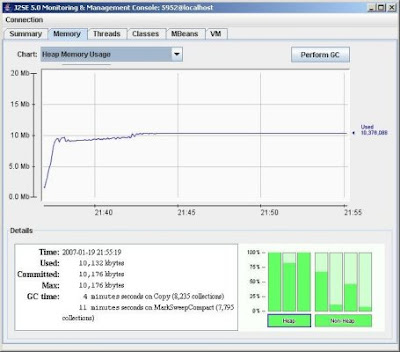
2) 2) With JRFileVirtualizer
exportFV:
[java] Filling time : 161170
[java] PDF creation time : 38355
[java] XML creation time : 14483
[java] HTML creation time : 17935
[java] CSV creation time : 5812
3) With JRSwapFileVirtualizer
exportSFV:
[java] Filling time : 51879
[java] PDF creation time : 32501
[java] XML creation time : 14405
[java] HTML creation time : 16579
[java] CSV creation time : 5365
4a) With GZipVirtualizer with lots of GC
exportGZV:
[java] Filling time : 84062
[java] Exception in thread "RMI TCP Connection(22)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(24)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(25)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(27)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Java Result: 1
4b) With GZipVirtualizer (max: 13MB)
exportGZV2:
[java] Filling time : 59297
[java] PDF creation time : 35594
[java] XML creation time : 16969
[java] HTML creation time : 19468
[java] CSV creation time : 10313
I have shared the updated virtualizer sample files at Updated Virtualizer Sample files
They are:
1) Pagination of the data and use of JRDataSource,
2) Viruatization of the report.
When there is a huge dataset, it is not a good idea to retrieve all the data at one time.The application will hog up the memory and you're application will go out of memory even before coming to the jasper report engine to fill up the data.To avoid that, the service layer/Db layer should return the data in pages and you gather the data in chunks and return the records in the chunks using JRDataSource interface, when the records are over in the current chunk, get the next chunk untilall the chunks gets over.When I meant JRDataSource, do not go for the Collection datasources, you implement the JRDataSource interface and provide the data through next() and getFieldValue()To provide an example, I just took the "virtualizer" example from the jasperReports sampleand modified a bit to demonstrate for this article.To know how to implement the JRDataSource, Have a look at the inner class "InnerDS" in the example.
Even after returning the data in chunks, finally the report has to be a single file.Jasper engine build the JasperPrint object for this. To avoid the piling up of memory at this stage, JasperReports provided a really cool feature called Virtualizer. Virtualizer basically serializes and writes the pages into file system to avoid the out of memory condition. There are 3 types of Virtualizer out there as of now. They are JRFileVirtualizer, JRSwapFileVirtualizer, and JRGzipVirtualizer.JRFileVirtualizer is a really simple virtualizer, where you need to mention the number of pages to keep in memory and the directory in which the Jasper Engine can swap the excess pages into files. Disadvantage with this Virtualizer is file handling overhead. This Virtualizer creates so many files during the process of virtualization and finally produces the required report file from those files.If the dataset is not that large, then you can go far JRFileVirtualizer.The second Virtualizer is JRSwapFileVirtualizer, which overcomes the disadvantage of JRFileVirtualizer. JRSwapFileVirtualizer creates only one swap file,which can be extended based on the size you specify. You have to specify the directory to swap, initial file size in number of blocks and the extension size for the JRSwapFile. Then while creating the JRSwapFileVirtualizer, provide the JRSwapFile as a parameter, and the number of pages to keep in memory. This Virtualizer is the best fit for the huge dataset.The Third Virtualizer is a special virtualizer which does not write the data into files, instead it compresses the jasper print object using the Gzip algorithm and reduces the memory consumption in the heap memory.The Ultimate Guide of JasperReports says that JRGzipVirtualizer can reduce the memory consumption by 1/10th. If you are dataset is not that big for sure and if you want to avoid the file I/O, you can go for JRGzipVirtualizer.
Check the sample to know more about the coding part. To keep it simple, I have reused the "virtualizer" sample and added the JRDataSource implementation with paging.I ran the sample that I have attached here for four scenarios. To tighten the limits to get the real effects, I ran the application with 10 MB as the max heap size (-Xmx10M).
1a) No Virtualizer, which ended up in out of memory with 10MB max heap size limit.
export:
[java] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
[java] Java Result: 1

1b) No Virtualizer with default heap size limit (64M)
export2:
[java] null
[java] Filling time : 44547
[java] PDF creation time : 22109
[java] XML creation time : 10157
[java] HTML creation time : 12281
[java] CSV creation time : 2078

2) 2) With JRFileVirtualizer
exportFV:
[java] Filling time : 161170
[java] PDF creation time : 38355
[java] XML creation time : 14483
[java] HTML creation time : 17935
[java] CSV creation time : 5812

3) With JRSwapFileVirtualizer
exportSFV:
[java] Filling time : 51879
[java] PDF creation time : 32501
[java] XML creation time : 14405
[java] HTML creation time : 16579
[java] CSV creation time : 5365

4a) With GZipVirtualizer with lots of GC
exportGZV:
[java] Filling time : 84062
[java] Exception in thread "RMI TCP Connection(22)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(24)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(25)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Exception in thread "RMI TCP Connection(27)-127.0.0.1" java.lang.OutOfMemoryError: Java heap space
[java] Java Result: 1

4b) With GZipVirtualizer (max: 13MB)
exportGZV2:
[java] Filling time : 59297
[java] PDF creation time : 35594
[java] XML creation time : 16969
[java] HTML creation time : 19468
[java] CSV creation time : 10313

I have shared the updated virtualizer sample files at Updated Virtualizer Sample files
Using Jasper Reports with Visual Web Pack
This tutorial illustrates the use of Jasper Reports with a Visual Web Pack application.
Register Jasper Reports library
Use the NetBeans Library Manager to create a library for the Jasper Reports class libraries. You need at least the following files from the distribution:
• dist/jasperreports-.jar
• lib/commons-beanutils-1.7.jar
• lib/commons-collections-2.1.jar
• lib/commons-digester-1.7.jar
• lib/commons-logging-1.0.2.jar
• lib/itext-1.3.1.jar
Register Jasper Reports image servlet
The image servlet is needed if you want html rendered reports (also without any graphical elements, because report placeholders uses images from this servlet). So you must register it in the web.xml configuration file. You can use the NetBeans web.xml editor to do so.
Servlet name : ImageServlet
Servlet class : net.sf.jasperreports.j2ee.servlets.ImageServlet
URL : /image
Insert methods for report output to application bean
The following methods in the application bean can be used to output a precompiled report as html or pdf. In this sample a collection of java objects is used as data source. For other data sources see the Jasper Reports documentation.
/**
* Output Jasper Report
*
* @param filename Precompiled report filename
* @param type Content type of report ("application/pdf" or "text/html")
* @param data Collection of value objects
*/
public void jasperReport( String filename, String type, Collection data ) {
jasperReport( filename, type, data, new HashMap() );
}
/**
* Output Jasper Report
*
* @param filename Precompiled report filename
* @param type Type of report ("application/pdf" or "text/html")
* @param data Collection of value objects
* @param params Map with parameters
*/
public void jasperReport( String filename, String type, Collection data, Map params ) {
final String[] VALID_TYPES = { "text/html", "application/pdf" };
// First check if type is supported
boolean found = false;
for ( int i = 0; i < VALID_TYPES.length; i++ ) {
if ( VALID_TYPES[i].equals( type ) ) {
found = true;
break;
}
}
if ( !found ) {
throw new IllegalArgumentException( "Report type '" + type + "' not supported." );
}
// InputStream for compiled report
ExternalContext econtext = getExternalContext();
InputStream stream = econtext.getResourceAsStream( filename );
if ( stream == null ) {
throw new IllegalArgumentException( "Report '" + filename + "' could not be opened." );
}
// Use collection as data source
JRBeanCollectionDataSource ds = new JRBeanCollectionDataSource( data );
JasperPrint jasperPrint = null;
try {
jasperPrint = JasperFillManager.fillReport( stream, params, ds );
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
} finally {
try {
stream.close();
} catch ( IOException e ) {
}
}
// Configure exporter and set parameters
JRExporter exporter = null;
HttpServletResponse response = (HttpServletResponse) econtext.getResponse();
FacesContext fcontext = FacesContext.getCurrentInstance();
try {
response.setContentType( type );
if ( "application/pdf".equals( type ) ) {
exporter = new JRPdfExporter();
exporter.setParameter( JRExporterParameter.JASPER_PRINT, jasperPrint );
exporter.setParameter( JRExporterParameter.OUTPUT_STREAM,
response.getOutputStream() );
} else if ( "text/html".equals( type ) ) {
exporter = new JRHtmlExporter();
exporter.setParameter( JRExporterParameter.JASPER_PRINT, jasperPrint );
exporter.setParameter( JRExporterParameter.OUTPUT_WRITER, response.getWriter() );
HttpServletRequest request = (HttpServletRequest)
fcontext.getExternalContext().getRequest();
request.getSession().setAttribute(
ImageServlet.DEFAULT_JASPER_PRINT_SESSION_ATTRIBUTE, jasperPrint );
exporter.setParameter( JRHtmlExporterParameter.IMAGES_MAP, new HashMap() );
exporter.setParameter(
JRHtmlExporterParameter.IMAGES_URI,
request.getContextPath() + "/image?image=" );
}
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
}
// Export report
try {
exporter.exportReport();
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
}
// Tell JavaServer faces that no more processing is necessary
fcontext.responseComplete();
}
Start report output from page bean
The output of a report can initiated from a ActionEvent with the following code:
try {
getApplicationBean().jasperReport(
"/reports/report.jasper",
"application/pdf",
getSessionBean().getSuchergebnisDataProvider().getList() );
} catch ( Exception e ) {
Logger.getLogger(getClass().getName()).severe( e.getMessage() );
Register Jasper Reports library
Use the NetBeans Library Manager to create a library for the Jasper Reports class libraries. You need at least the following files from the distribution:
• dist/jasperreports-
• lib/commons-beanutils-1.7.jar
• lib/commons-collections-2.1.jar
• lib/commons-digester-1.7.jar
• lib/commons-logging-1.0.2.jar
• lib/itext-1.3.1.jar
Register Jasper Reports image servlet
The image servlet is needed if you want html rendered reports (also without any graphical elements, because report placeholders uses images from this servlet). So you must register it in the web.xml configuration file. You can use the NetBeans web.xml editor to do so.
Servlet name : ImageServlet
Servlet class : net.sf.jasperreports.j2ee.servlets.ImageServlet
URL : /image
Insert methods for report output to application bean
The following methods in the application bean can be used to output a precompiled report as html or pdf. In this sample a collection of java objects is used as data source. For other data sources see the Jasper Reports documentation.
/**
* Output Jasper Report
*
* @param filename Precompiled report filename
* @param type Content type of report ("application/pdf" or "text/html")
* @param data Collection of value objects
*/
public void jasperReport( String filename, String type, Collection data ) {
jasperReport( filename, type, data, new HashMap() );
}
/**
* Output Jasper Report
*
* @param filename Precompiled report filename
* @param type Type of report ("application/pdf" or "text/html")
* @param data Collection of value objects
* @param params Map with parameters
*/
public void jasperReport( String filename, String type, Collection data, Map params ) {
final String[] VALID_TYPES = { "text/html", "application/pdf" };
// First check if type is supported
boolean found = false;
for ( int i = 0; i < VALID_TYPES.length; i++ ) {
if ( VALID_TYPES[i].equals( type ) ) {
found = true;
break;
}
}
if ( !found ) {
throw new IllegalArgumentException( "Report type '" + type + "' not supported." );
}
// InputStream for compiled report
ExternalContext econtext = getExternalContext();
InputStream stream = econtext.getResourceAsStream( filename );
if ( stream == null ) {
throw new IllegalArgumentException( "Report '" + filename + "' could not be opened." );
}
// Use collection as data source
JRBeanCollectionDataSource ds = new JRBeanCollectionDataSource( data );
JasperPrint jasperPrint = null;
try {
jasperPrint = JasperFillManager.fillReport( stream, params, ds );
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
} finally {
try {
stream.close();
} catch ( IOException e ) {
}
}
// Configure exporter and set parameters
JRExporter exporter = null;
HttpServletResponse response = (HttpServletResponse) econtext.getResponse();
FacesContext fcontext = FacesContext.getCurrentInstance();
try {
response.setContentType( type );
if ( "application/pdf".equals( type ) ) {
exporter = new JRPdfExporter();
exporter.setParameter( JRExporterParameter.JASPER_PRINT, jasperPrint );
exporter.setParameter( JRExporterParameter.OUTPUT_STREAM,
response.getOutputStream() );
} else if ( "text/html".equals( type ) ) {
exporter = new JRHtmlExporter();
exporter.setParameter( JRExporterParameter.JASPER_PRINT, jasperPrint );
exporter.setParameter( JRExporterParameter.OUTPUT_WRITER, response.getWriter() );
HttpServletRequest request = (HttpServletRequest)
fcontext.getExternalContext().getRequest();
request.getSession().setAttribute(
ImageServlet.DEFAULT_JASPER_PRINT_SESSION_ATTRIBUTE, jasperPrint );
exporter.setParameter( JRHtmlExporterParameter.IMAGES_MAP, new HashMap() );
exporter.setParameter(
JRHtmlExporterParameter.IMAGES_URI,
request.getContextPath() + "/image?image=" );
}
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
}
// Export report
try {
exporter.exportReport();
} catch ( RuntimeException e ) {
throw e;
} catch ( Exception e ) {
throw new FacesException( e );
}
// Tell JavaServer faces that no more processing is necessary
fcontext.responseComplete();
}
Start report output from page bean
The output of a report can initiated from a ActionEvent with the following code:
try {
getApplicationBean().jasperReport(
"/reports/report.jasper",
"application/pdf",
getSessionBean().getSuchergebnisDataProvider().getList() );
} catch ( Exception e ) {
Logger.getLogger(getClass().getName()).severe( e.getMessage() );
Using Hibernate queries with JasperReports
Introduction
In the article, we examine a performance-optimised approach for using Hibernate queries to generate reports with JasperReports.
JasperReports is a powerful and flexible Open Source reporting tool. Combined with the graphical design tool iReport, for example, you get a complete Java Open Source reporting solution. In this article, we will investigate how you can integrate JasperReports reporting with Hibernate data sources in an optimal manner, without sacrificing ease-of-use or performance.
Basic Hibernate/JasperReports integration
To integrate Hibernate and JasperReports, you have to define a JasperReports data source. One simple and intuitive approach is to use the JRBeanCollectionDataSource data source (This approach is presented here) :
List results = session.find("from com.acme.Sale");
Map parameters = new HashMap();
parameters.put("Title", "Sales Report");
InputStream reportStream
= this.class.getResourceAsStream("/sales-report.xml");
JasperDesign jasperDesign = JasperManager.loadXmlDesign(reportStream);
JasperReport jasperReport = JasperManager.compileReport(jasperDesign);
JRBeanCollectionDataSource ds = new JRBeanCollectionDataSource(results);
JasperPrint jasperPrint = JasperManager.fillReport(jasperReport,
parameters,
ds);
JasperExportManager.exportReportToPdfFile(jasperPrint, "sales-report.pdf");
This approach will work well for small lists. However, for reports involving tens or hundreds of thousands of lines, it is inefficiant, memory-consuming, and slow. Indeed, experience shows that, when running on a standard Tomcat configuration, a list returning as few as 10000 business objects can cause OutOfMemory exceptions. It also wastes time building a bulky list of objects before processing them, and pollutes the Hibernate session (and possibly second-level caches with temporary objects.
Optimised Hibernate/JasperReports integration
We need a way to efficiently read and process Hibernate queries, without creating too many unnecessary temporary objects in memory. One possible way to do this is the following :
Define an optimised layer for executing Hibernate queries efficiently
Define an abstraction layer for these classes which is compatible with JasperReports
Wrap this data access layer in a JasperReports class that can be directly plugged into JasperReports
The Hibernate Data Access Layer : The QueryProvider interface and its implementations
We start with the optimised Hibernate data access. (you may note that this layer is not actually Hibernate-specific, so other implementations could implement other types of data access without impacting the design).
This layer contains two principal classes :
The CriteriaSet class
The QueryProvider interface
A CriteriaSet is simply a JavaBean which contains parameters which may be passed to the Hibernate query. It is simply a generic way of encapsulating a set of parameters. A QueryProvider provides a generic way of returning an arbitrary subset of the query results set. The essential point is that query results are read in small chunks, not all at once. This allows more efficient memory handling and better performance.
/**
* A QueryProvidor provides a generic way of fetching a set of objects.
*/
public interface QueryProvider {
/**
* Return a set of objects based on a given criteria set.
* @param firstResult the first result to be returned
* @param maxResults the maximum number of results to be returned
* @return a list of objects
*/
List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults) throws HibernateException;
}
A typical implementation of this class simply builds a Hibernate query using the specified criteria set and returns the requested subset of results. For example :
public class ProductQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults)
throws HibernateException {
//
// Build query criteria
//
Session sess = SessionManager.currentSession();
ProductCriteriaSet productCriteria
= (ProductCriteriaSet) criteria;
Query query = session.find("from com.acme.Product p "
+ "where p.categoryCode = :categoryCode ");
query.setParameter("categoryCode",
productCriteria.getCategoryCode();
return query.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
}
A more sophisticated implementation is helpful for dynamic queries. We define an abstract BaseQueryProvider class which can be used for dynamic query generation. This is typically useful when the report has to be generated using several parameters, some of which are optionnal.. Each derived class overrides the buildCriteria() method. This method builds a Hibernate Criteria object using the specified Criteria set as appropriate :
public abstract class BaseQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria, int firstResult, int maxResults)
throws HibernateException {
Session sess = SessionManager.currentSession();
Criteria queryCriteria = buildCriteria(criteria, sess);
return queryCriteria.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
protected abstract Criteria buildCriteria(CriteriaSet criteria, Session sess);
}
A typical implementation is shown here :
public class SalesQueryProvider extends BaseQueryProvider {
protected Criteria buildCriteria(CriteriaSet criteria,
Session sess) {
//
// Build query criteria
//
SalesCriteriaSet salesCriteria
= (SalesCriteriaSet) criteria;
Criteria queryCriteria
= sess.createCriteria(Sale.class);
if (salesCriteria.getStartDate() != null) {
queryCriteria.add(
Expression.eq("getStartDate",
salesCriteria.getStartDate()));
}
// etc...
return queryCriteria;
}
}
Note that a QueryProvider does not need to return Hibernate-persisted objects. Large-volume queries can sometimes be more efficiently implemented by returning custom-made JavaBeans containing just the required columns. HQL allows you to to this quite easily :
public class CityQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults)
throws HibernateException {
//
// Build query criteria
//
Session sess = SessionManager.currentSession();
Query query
= session.find(
"select new CityItem(city.id, "
+ " city.name, "
+ " city.electrityCompany.name) "
+ " from City city "
+ " left join city.electrityCompany");
return query.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
}
Hibernate data access abstraction : the ReportDataSource interface
Next, we define a level of abstraction between the Hibernate querying and the JasperReport classes. The ReportDataSource does this :
public interface ReportDataSource extends Serializable {
Object getObject(int index);
}
The standard implementation of this interface reads Hibernate objects using a given QueryProvider and returns them to JasperReports one by one. Here is the source code of this class (getters, setters, logging code and error-handling code have been removed for clarty) :
public class ReportDataSourceImpl implements ReportDataSource {
private CriteriaSet criteriaSet;
private QueryProvider queryProvider;
private List resultPage;
private int pageStart = Integer.MAX_VALUE;
private int pageEnd = Integer.MIN_VALUE;
private static final int PAGE_SIZE = 50;
//
// Getters and setters for criteriaSet and queryProvider
//
...
public List getObjects(int firstResult,
int maxResults) {
List queryResults = getQueryProvider()
.getObjects(getCriteriaSet(),
firstResult,
maxResults);
if (resultPage == null) {
resultPage = new ArrayList(queryResults.size());
}
resultPage.clear();
for(int i = 0; i < queryResults.size(); i++) {
resultPage.add(queryResults.get(i));
}
pageStart = firstResult;
pageEnd = firstResult + queryResults.size() - 1;
return resultPage;
}
public final Object getObject(int index) {
if ((resultPage == null)
|| (index < pageStart)
|| (index > pageEnd)) {
resultPage = getObjects(index, PAGE_SIZE);
}
Object result = null;
int pos = index - pageStart;
if ((resultPage != null)
&& (resultPage.size() > pos)) {
result = resultPage.get(pos);
}
return result;
}
}
Finally, we have to be able to call the Hibernate data source from JasperReports. To do so, we start by looking at the JasperManager fillReport() method, which takes a JRDataSource object as its third parameter and uses it to generate the report :
JasperPrint jasperPrint = JasperManager.fillReport(jasperReport, parameters, ds);
To implement our own optimised JRDataSource, we extended the JRAbstractBeanDataSource class. This class is presented here (logging and error-handling code has been removed for clarty).
public class ReportSource extends JRAbstractBeanDataSource {
private ReportDataSource dataSource;
protected int index = 0;
protected Object bean;
private static Map fieldNameMap = new HashMap();
public ReportSource(ReportDataSource dataSource) {
super(true);
this.dataSource = dataSource;
index = 0;
}
public boolean next() throws JRException {
bean = dataSource.getObject(index++);
return (bean != null);
}
public void moveFirst() throws JRException {
index = 0;
bean = dataSource.getObject(index);
}
public Object getFieldValue(JRField field) throws JRException {
String nameField = getFieldName(field.getName());
return PropertyUtils.getProperty(bean, nameField);
}
/**
* Replace the character "_" by a ".".
*
* @param fieldName the name of the field
* @return the value in the cache or make
* the replacement and return this value
*/
private String getFieldName(String fieldName) {
String filteredFieldName
= (String) fieldNameMap.get(fieldName);
if (filteredFieldName == null) {
filteredFieldName = fieldName.replace('_','.');
fieldNameMap.put(fieldName,filteredFieldName);
}
return filteredFieldName;
}
}
This class is basically just a proxy between JasperReports and the Hibernate data source object. The only tricky bit is field name handling. For some reason, JasperReports does not accept field names containing dots (ex. "product.code"). However, when you retrieve a set of Hibernate-persisted business objects, you often need to access object attributes. To get around this, we replace the "." by a "_" in the JasperReport template (ex. "product_code" instead of "product.code"), and convert back to a conventional JavaBean format in the getFieldName() method.
Putting it all together
So, when you put it all together, you get something like this :
List results = session.find("from com.acme.Sale");
Map parameters = new HashMap();
parameters.put("Title", "Sales Report");
InputStream reportStream
= this.class.getResourceAsStream("/sales-report.xml");
JasperDesign jasperDesign
= JasperManager.loadXmlDesign(reportStream);
JasperReport jasperReport
= JasperManager.compileReport(jasperDesign);
ReportDataSource hibernateDataSource
= new ReportDataSourceImpl();
hibernateDataSource.setQueryProvider(new SalesQueryProvider());
hibernateDataSource.setCriteriaSet(salesCriteria);
ReportSource rs = new ReportSource(hibernateDataSource);
JasperPrint jasperPrint
= JasperManager.fillReport(jasperReport,
parameters,
rs);
JasperExportManager.exportReportTsoPdfFile(jasperPrint,
"sales-report.pdf");
Further JasperReports optimisations
Compiled Report caching
In the previous code, the JasperReport is loaded and compiled before it is run. In a serverside application, for optimal performance, the reports should be loaded and compiled once and then cached. This will save several seconds on each query generation.
Optimising Hibernate Queries
The first cause of slow report generation is sub-optimal querying. Hibernate is a high-performance persistence library which gives excellent results when correctly used. So you should treate any report which takes an excessive time to generate as suspicious. Common Hibernate optimisation strategies include :
Correct use of joins
Correct use of lazy associations
Reading a subset of columns rather than whole Hibernate-persisted objects
Some Hibernate query optimisation techniques are discussed here.
In the article, we examine a performance-optimised approach for using Hibernate queries to generate reports with JasperReports.
JasperReports is a powerful and flexible Open Source reporting tool. Combined with the graphical design tool iReport, for example, you get a complete Java Open Source reporting solution. In this article, we will investigate how you can integrate JasperReports reporting with Hibernate data sources in an optimal manner, without sacrificing ease-of-use or performance.
Basic Hibernate/JasperReports integration
To integrate Hibernate and JasperReports, you have to define a JasperReports data source. One simple and intuitive approach is to use the JRBeanCollectionDataSource data source (This approach is presented here) :
List results = session.find("from com.acme.Sale");
Map parameters = new HashMap();
parameters.put("Title", "Sales Report");
InputStream reportStream
= this.class.getResourceAsStream("/sales-report.xml");
JasperDesign jasperDesign = JasperManager.loadXmlDesign(reportStream);
JasperReport jasperReport = JasperManager.compileReport(jasperDesign);
JRBeanCollectionDataSource ds = new JRBeanCollectionDataSource(results);
JasperPrint jasperPrint = JasperManager.fillReport(jasperReport,
parameters,
ds);
JasperExportManager.exportReportToPdfFile(jasperPrint, "sales-report.pdf");
This approach will work well for small lists. However, for reports involving tens or hundreds of thousands of lines, it is inefficiant, memory-consuming, and slow. Indeed, experience shows that, when running on a standard Tomcat configuration, a list returning as few as 10000 business objects can cause OutOfMemory exceptions. It also wastes time building a bulky list of objects before processing them, and pollutes the Hibernate session (and possibly second-level caches with temporary objects.
Optimised Hibernate/JasperReports integration
We need a way to efficiently read and process Hibernate queries, without creating too many unnecessary temporary objects in memory. One possible way to do this is the following :
Define an optimised layer for executing Hibernate queries efficiently
Define an abstraction layer for these classes which is compatible with JasperReports
Wrap this data access layer in a JasperReports class that can be directly plugged into JasperReports
The Hibernate Data Access Layer : The QueryProvider interface and its implementations
We start with the optimised Hibernate data access. (you may note that this layer is not actually Hibernate-specific, so other implementations could implement other types of data access without impacting the design).
This layer contains two principal classes :
The CriteriaSet class
The QueryProvider interface
A CriteriaSet is simply a JavaBean which contains parameters which may be passed to the Hibernate query. It is simply a generic way of encapsulating a set of parameters. A QueryProvider provides a generic way of returning an arbitrary subset of the query results set. The essential point is that query results are read in small chunks, not all at once. This allows more efficient memory handling and better performance.
/**
* A QueryProvidor provides a generic way of fetching a set of objects.
*/
public interface QueryProvider {
/**
* Return a set of objects based on a given criteria set.
* @param firstResult the first result to be returned
* @param maxResults the maximum number of results to be returned
* @return a list of objects
*/
List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults) throws HibernateException;
}
A typical implementation of this class simply builds a Hibernate query using the specified criteria set and returns the requested subset of results. For example :
public class ProductQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults)
throws HibernateException {
//
// Build query criteria
//
Session sess = SessionManager.currentSession();
ProductCriteriaSet productCriteria
= (ProductCriteriaSet) criteria;
Query query = session.find("from com.acme.Product p "
+ "where p.categoryCode = :categoryCode ");
query.setParameter("categoryCode",
productCriteria.getCategoryCode();
return query.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
}
A more sophisticated implementation is helpful for dynamic queries. We define an abstract BaseQueryProvider class which can be used for dynamic query generation. This is typically useful when the report has to be generated using several parameters, some of which are optionnal.. Each derived class overrides the buildCriteria() method. This method builds a Hibernate Criteria object using the specified Criteria set as appropriate :
public abstract class BaseQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria, int firstResult, int maxResults)
throws HibernateException {
Session sess = SessionManager.currentSession();
Criteria queryCriteria = buildCriteria(criteria, sess);
return queryCriteria.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
protected abstract Criteria buildCriteria(CriteriaSet criteria, Session sess);
}
A typical implementation is shown here :
public class SalesQueryProvider extends BaseQueryProvider {
protected Criteria buildCriteria(CriteriaSet criteria,
Session sess) {
//
// Build query criteria
//
SalesCriteriaSet salesCriteria
= (SalesCriteriaSet) criteria;
Criteria queryCriteria
= sess.createCriteria(Sale.class);
if (salesCriteria.getStartDate() != null) {
queryCriteria.add(
Expression.eq("getStartDate",
salesCriteria.getStartDate()));
}
// etc...
return queryCriteria;
}
}
Note that a QueryProvider does not need to return Hibernate-persisted objects. Large-volume queries can sometimes be more efficiently implemented by returning custom-made JavaBeans containing just the required columns. HQL allows you to to this quite easily :
public class CityQueryProvider implements QueryProvider {
public List getObjects(CriteriaSet criteria,
int firstResult,
int maxResults)
throws HibernateException {
//
// Build query criteria
//
Session sess = SessionManager.currentSession();
Query query
= session.find(
"select new CityItem(city.id, "
+ " city.name, "
+ " city.electrityCompany.name) "
+ " from City city "
+ " left join city.electrityCompany");
return query.setCacheable(true)
.setFirstResult(firstResult)
.setMaxResults(maxResults)
.setFetchSize(100)
.list();
}
}
Hibernate data access abstraction : the ReportDataSource interface
Next, we define a level of abstraction between the Hibernate querying and the JasperReport classes. The ReportDataSource does this :
public interface ReportDataSource extends Serializable {
Object getObject(int index);
}
The standard implementation of this interface reads Hibernate objects using a given QueryProvider and returns them to JasperReports one by one. Here is the source code of this class (getters, setters, logging code and error-handling code have been removed for clarty) :
public class ReportDataSourceImpl implements ReportDataSource {
private CriteriaSet criteriaSet;
private QueryProvider queryProvider;
private List resultPage;
private int pageStart = Integer.MAX_VALUE;
private int pageEnd = Integer.MIN_VALUE;
private static final int PAGE_SIZE = 50;
//
// Getters and setters for criteriaSet and queryProvider
//
...
public List getObjects(int firstResult,
int maxResults) {
List queryResults = getQueryProvider()
.getObjects(getCriteriaSet(),
firstResult,
maxResults);
if (resultPage == null) {
resultPage = new ArrayList(queryResults.size());
}
resultPage.clear();
for(int i = 0; i < queryResults.size(); i++) {
resultPage.add(queryResults.get(i));
}
pageStart = firstResult;
pageEnd = firstResult + queryResults.size() - 1;
return resultPage;
}
public final Object getObject(int index) {
if ((resultPage == null)
|| (index < pageStart)
|| (index > pageEnd)) {
resultPage = getObjects(index, PAGE_SIZE);
}
Object result = null;
int pos = index - pageStart;
if ((resultPage != null)
&& (resultPage.size() > pos)) {
result = resultPage.get(pos);
}
return result;
}
}
Finally, we have to be able to call the Hibernate data source from JasperReports. To do so, we start by looking at the JasperManager fillReport() method, which takes a JRDataSource object as its third parameter and uses it to generate the report :
JasperPrint jasperPrint = JasperManager.fillReport(jasperReport, parameters, ds);
To implement our own optimised JRDataSource, we extended the JRAbstractBeanDataSource class. This class is presented here (logging and error-handling code has been removed for clarty).
public class ReportSource extends JRAbstractBeanDataSource {
private ReportDataSource dataSource;
protected int index = 0;
protected Object bean;
private static Map fieldNameMap = new HashMap();
public ReportSource(ReportDataSource dataSource) {
super(true);
this.dataSource = dataSource;
index = 0;
}
public boolean next() throws JRException {
bean = dataSource.getObject(index++);
return (bean != null);
}
public void moveFirst() throws JRException {
index = 0;
bean = dataSource.getObject(index);
}
public Object getFieldValue(JRField field) throws JRException {
String nameField = getFieldName(field.getName());
return PropertyUtils.getProperty(bean, nameField);
}
/**
* Replace the character "_" by a ".".
*
* @param fieldName the name of the field
* @return the value in the cache or make
* the replacement and return this value
*/
private String getFieldName(String fieldName) {
String filteredFieldName
= (String) fieldNameMap.get(fieldName);
if (filteredFieldName == null) {
filteredFieldName = fieldName.replace('_','.');
fieldNameMap.put(fieldName,filteredFieldName);
}
return filteredFieldName;
}
}
This class is basically just a proxy between JasperReports and the Hibernate data source object. The only tricky bit is field name handling. For some reason, JasperReports does not accept field names containing dots (ex. "product.code"). However, when you retrieve a set of Hibernate-persisted business objects, you often need to access object attributes. To get around this, we replace the "." by a "_" in the JasperReport template (ex. "product_code" instead of "product.code"), and convert back to a conventional JavaBean format in the getFieldName() method.
Putting it all together
So, when you put it all together, you get something like this :
List results = session.find("from com.acme.Sale");
Map parameters = new HashMap();
parameters.put("Title", "Sales Report");
InputStream reportStream
= this.class.getResourceAsStream("/sales-report.xml");
JasperDesign jasperDesign
= JasperManager.loadXmlDesign(reportStream);
JasperReport jasperReport
= JasperManager.compileReport(jasperDesign);
ReportDataSource hibernateDataSource
= new ReportDataSourceImpl();
hibernateDataSource.setQueryProvider(new SalesQueryProvider());
hibernateDataSource.setCriteriaSet(salesCriteria);
ReportSource rs = new ReportSource(hibernateDataSource);
JasperPrint jasperPrint
= JasperManager.fillReport(jasperReport,
parameters,
rs);
JasperExportManager.exportReportTsoPdfFile(jasperPrint,
"sales-report.pdf");
Further JasperReports optimisations
Compiled Report caching
In the previous code, the JasperReport is loaded and compiled before it is run. In a serverside application, for optimal performance, the reports should be loaded and compiled once and then cached. This will save several seconds on each query generation.
Optimising Hibernate Queries
The first cause of slow report generation is sub-optimal querying. Hibernate is a high-performance persistence library which gives excellent results when correctly used. So you should treate any report which takes an excessive time to generate as suspicious. Common Hibernate optimisation strategies include :
Correct use of joins
Correct use of lazy associations
Reading a subset of columns rather than whole Hibernate-persisted objects
Some Hibernate query optimisation techniques are discussed here.
Subscribe to:
Posts (Atom)