Should you throw an exception, or return null? Should you use checked or unchecked exceptions? For many novice to mid-level developers, exception handling tends to be an afterthought. Their typical pattern is usually a simple try/catch/printStackTrace(). When they try to get more creative, they usually stumble into one or more common exception handling antipatterns.
The antipattern concept became popular in the software development community with the release of AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis in 1998. An antipattern draws on real-world experience to identify a commonly occurring programming mistake. It describes the general form of the bad pattern, identifies its negative consequences, prescribes a remedy, and helps define a common vocabulary by giving each pattern a name.
In this article, we'll discuss some fundamental concepts about the different types of Java exceptions and their intended uses. We'll also cover basic logging concepts, especially as they relate to exception handling. Finally, instead of prescribing what to do, we'll focus on what not to do, and take a look at a dozen common exception-handling antipatterns that you are almost certain to find somewhere in your code base.
Basic Exception Concepts
One of the most important concepts about exception handling to understand is that there are three general types of throwable classes in Java: checked exceptions, unchecked exceptions, and errors.
Checked exceptions are exceptions that must be declared in the throws clause of a method. They extend Exception and are intended to be an "in your face" type of exceptions. A checked exception indicates an expected problem that can occur during normal system operation. Some examples are problems communicating with external systems, and problems with user input. Note that, depending on your code's intended function, "user input" may refer to a user interface, or it may refer to the parameters that another developer passes to your API. Often, the correct response to a checked exception is to try again later, or to prompt the user to modify his input.
Unchecked exceptions are exceptions that do not need to be declared in a throws clause. They extend RuntimeException. An unchecked exception indicates an unexpected problem that is probably due to a bug in the code. The most common example is a NullPointerException. There are many core exceptions in the JDK that are checked exceptions but really shouldn't be, such as IllegalAccessException and NoSuchMethodException. An unchecked exception probably shouldn't be retried, and the correct response is usually to do nothing, and let it bubble up out of your method and through the execution stack. This is why it doesn't need to be declared in a throws clause. Eventually, at a high level of execution, the exception should probably be logged (see below).
Errors are serious problems that are almost certainly not recoverable. Some examples are OutOfMemoryError, LinkageError, and StackOverflowError.
Creating Your Own Exceptions
Most packages and/or system components should contain one or more custom exception classes. There are two primary use cases for a custom exception. First, your code can simply throw the custom exception when something goes wrong. For example:
throw new MyObjectNotFoundException("Couldn't find
object id " + id);
Second, your code can wrap and throw another exception. For example:
catch (NoSuchMethodException e) {
throw new MyServiceException("Couldn't process
request", e);
}
Wrapping an exception can provide extra information to the user by adding your own message (as in the example above), while still preserving the stack trace and message of the original exception. It also allows you to hide the implementation details of your code, which is the most important reason to wrap exceptions. For instance, look at the Hibernate API. Even though Hibernate makes extensive use of JDBC in its implementation, and most of the operations that it performs can throw SQLException, Hibernate does not expose SQLException anywhere in its API. Instead, it wraps these exceptions inside of various subclasses of HibernateException. Using the approach allows you to change the underlying implementation of your module without modifying its public API.
Exceptions and Transactions
EJB 2
The creators of the EJB 2 specification decided to make use of the distinction between checked and unchecked exceptions to determine whether or not to roll back the active transaction. If an EJB throws a checked exception, the transaction still commits normally. If an EJB throws an unchecked exception, the transaction is rolled back. You almost always want an exception to roll back the active transaction. It just helps to be aware of this fact when working with EJBs.
EJB 3
To somewhat alleviate the problem that I just described, EJB 3 has added an ApplicationException annotation with a rollback element. This gives you explicit control over whether or not your exception (either checked or unchecked) should roll back the transaction. For example:
@ApplicationException(rollback=true)
public class FooException extends Exception
...
Message-Driven Beans
Be aware that when working with message-driven beans (MDBs) that are driven by a queue, rolling back the active transaction also places the message that you are currently processing back on the queue. The message will then be redelivered to another MDB, possibly on another machine, if your app servers are clustered. It will be retried until it hits the app server's retry limit, at which point the message is left on the dead letter queue. If your MDB wants to avoid reprocessing (e.g., because it performs an expensive operation), it can call getJMSRedelivered() on the message, and if it was redelivered, it can just throw it away.
Logging
When your code encounters an exception, it must either handle it, let it bubble up, wrap it, or log it. If your code can programmatically handle an exception (e.g., retry in the case of a network failure), then it should. If it can't, it should generally either let it bubble up (for unchecked exceptions) or wrap it (for checked exceptions). However, it is ultimately going to be someone's responsibility to log the fact that this exception occurred if nobody in the calling stack was able to handle it programmatically. This code should typically live as high in the execution stack as it can. Some examples are the onMessage() method of an MDB, and the main() method of a class. Once you catch the exception, you should log it appropriately.
The JDK has a java.util.logging package built in, although the Log4j project from Apache continues to be a commonly-used alternative. Apache also offers the Commons Logging project, which acts as a thin layer that allows you to swap out different logging implementations underneath in a pluggable fashion. All of these logging frameworks that I've mentioned have basically equivalent levels:
* FATAL: Should be used in extreme cases, where immediate attention is needed. This level can be useful to trigger a support engineer's pager.
* ERROR: Indicates a bug, or a general error condition, but not necessarily one that brings the system to a halt. This level can be useful to trigger email to an alerts list, where it can be filed as a bug by a support engineer.
* WARN: Not necessarily a bug, but something someone will probably want to know about. If someone is reading a log file, they will typically want to see any warnings that arise.
* INFO: Used for basic, high-level diagnostic information. Most often good to stick immediately before and after relatively long-running sections of code to answer the question "What is the app doing?" Messages at this level should avoid being very chatty.
* DEBUG: Used for low-level debugging assistance.
If you are using commons-logging or Log4j, watch out for a common gotcha. The error, warn, info, and debug methods are overloaded with one version that takes only a message parameter, and one that also takes a Throwable as the second parameter. Make sure that if you are trying to log the fact that an exception was thrown, you pass both a message and the exception. If you call the version that accepts a single parameter, and pass it the exception, it hides the stack trace of the exception.
When calling log.debug(), it's good practice to always surround the call with a check for log.isDebugEnabled(). This is purely for optimization. It's simply a good habit to get into, and once you do it for a few days, it will just become automatic.
Do not use System.out or System.err. You should always use a logger. Loggers are extremely configurable and flexible, and each appender can decide which level of severity it wants to report/act on, on a package-by-package basis. Printing a message to System.out is just sloppy and generally unforgivable.
Antipatterns
Log and Throw
Example:
catch (NoSuchMethodException e) {
LOG.error("Blah", e);
throw e;
}
or
catch (NoSuchMethodException e) {
LOG.error("Blah", e);
throw new MyServiceException("Blah", e);
}
or
catch (NoSuchMethodException e) {
e.printStackTrace();
throw new MyServiceException("Blah", e);
}
All of the above examples are equally wrong. This is one of the most annoying error-handling antipatterns. Either log the exception, or throw it, but never do both. Logging and throwing results in multiple log messages for a single problem in the code, and makes life hell for the support engineer who is trying to dig through the logs.
Throwing Exception
Example:
public void foo() throws Exception {
This is just sloppy, and it completely defeats the purpose of using a checked exception. It tells your callers "something can go wrong in my method." Real useful. Don't do this. Declare the specific checked exceptions that your method can throw. If there are several, you should probably wrap them in your own exception (see "Throwing the Kitchen Sink" below.)
Throwing the Kitchen Sink
Example:
public void foo() throws MyException,
AnotherException, SomeOtherException,
YetAnotherException
{
Throwing multiple checked exceptions from your method is fine, as long as there are different possible courses of action that the caller may want to take, depending on which exception was thrown. If you have multiple checked exceptions that basically mean the same thing to the caller, wrap them in a single checked exception.
Catching Exception
Example:
try {
foo();
} catch (Exception e) {
LOG.error("Foo failed", e);
}
This is generally wrong and sloppy. Catch the specific exceptions that can be thrown. The problem with catching Exception is that if the method you are calling later adds a new checked exception to its method signature, the developer's intent is that you should handle the specific new exception. If your code just catches Exception (or worse, Throwable), you'll probably never know about the change and the fact that your code is now wrong.
Destructive Wrapping
Example:
catch (NoSuchMethodException e) {
throw new MyServiceException("Blah: " +
e.getMessage());
}
This destroys the stack trace of the original exception, and is always wrong.
Log and Return Null
Example:
catch (NoSuchMethodException e) {
LOG.error("Blah", e);
return null;
}
or
catch (NoSuchMethodException e) {
e.printStackTrace();
return null;
} // Man I hate this one
Although not always incorrect, this is usually wrong. Instead of returning null, throw the exception, and let the caller deal with it. You should only return null in a normal (non-exceptional) use case (e.g., "This method returns null if the search string was not found.").
Catch and Ignore
Example:
catch (NoSuchMethodException e) {
return null;
}
This one is insidious. Not only does it return null instead of handling or re-throwing the exception, it totally swallows the exception, losing the information forever.
Throw from Within Finally
Example:
try {
blah();
} finally {
cleanUp();
}
This is fine, as long as cleanUp() can never throw an exception. In the above example, if blah() throws an exception, and then in the finally block, cleanUp() throws an exception, that second exception will be thrown and the first exception will be lost forever. If the code that you call in a finally block can possibly throw an exception, make sure that you either handle it, or log it. Never let it bubble out of the finally block.
Multi-Line Log Messages
Example:
LOG.debug("Using cache policy A");
LOG.debug("Using retry policy B");
Always try to group together all log messages, regardless of the level, into as few calls as possible. So in the example above, the correct code would look like:
LOG.debug("Using cache policy A, using retry policy B");
Using a multi-line log message with multiple calls to log.debug() may look fine in your test case, but when it shows up in the log file of an app server with 500 threads running in parallel, all spewing information to the same log file, your two log messages may end up spaced out 1000 lines apart in the log file, even though they occur on subsequent lines in your code.
Unsupported Operation Returning Null
Example:
public String foo() {
// Not supported in this implementation.
return null;
}
When you're implementing an abstract base class, and you're just providing hooks for subclasses to optionally override, this is fine. However, if this is not the case, you should throw an UnsupportedOperationException instead of returning null. This makes it much more obvious to the caller why things aren't working, instead of her having to figure out why her code is throwing some random NullPointerException.
Ignoring InterruptedException
Example:
while (true) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {}
doSomethingCool();
}
InterruptedException is a clue to your code that it should stop whatever it's doing. Some common use cases for a thread getting interrupted are the active transaction timing out, or a thread pool getting shut down. Instead of ignoring the InterruptedException, your code should do its best to finish up what it's doing, and finish the current thread of execution. So to correct the example above:
while (true) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
break;
}
doSomethingCool();
}
Relying on getCause()
Example:
catch (MyException e) {
if (e.getCause() instanceof FooException) {
...
The problem with relying on the result of getCause is that it makes your code fragile. It may work fine today, but what happens when the code that you're calling into, or the code that it relies on, changes its underlying implementation, and ends up wrapping the ultimate cause inside of another exception? Now calling getCause may return you a wrapping exception, and what you really want is the result of getCause().getCause(). Instead, you should unwrap the causes until you find the ultimate cause of the problem. Apache's commons-lang project provides ExceptionUtils.getRootCause() to do this easily.
Conclusion
Good exception handling is a key to building robust, reliable systems. Avoiding the antipatterns that we've outlined here helps you build systems that are maintainable, resilient to change, and that play well with other systems.
Tim McCune is a Software Engineer with Adapt Technologies in Pasadena, CA.
(http://today.java.net/pub/a/today/2006/04/06/exception-handling-antipatterns.html )
Sunday, April 16, 2006
The Java open source debate By Andy Roberts
The recent announcement [http://mail-archives.apache.org/mod_mbox/incubator-general/200505.mbox/%3CCA4BEB82-3D84-457D-9531-1477DD749919@apache.org%3E] from Apache regarding their plans to embark on their own J2SE implementation called Harmony has re-ignited the long-running Java/OSS debate. James "Father of Java" Gosling reacted in an unexpected way by giving a misleading view of what open source is really all about. Now that the dust has settled a little bit, it's time for an article that is not championing the cause for the relicensing of Sun's implementation under more permissive, open source terms, but simply a look at what could (and could not) happen under the open source model.
Java, Page 1/2
Whilst obviously aiming to be as objective as possible, I think it fair to let you know my leanings. I'm a big OSS fan. I've been using various forms of the GNU/Linux platform for around 8 years. I'm not a purist though: I will use propriety products if it does the job. Proof of this is that I am also a big Java fan. I started learning it around 5 years ago, although it's the last 3 years or so that it's been my main language. I honestly don't have an issue with the Java team, or Sun in general about their decisions. I don't always agree with their approach, specifically their licenses, but I don't mean to be anti-Sun, even if it should appear that way in this article (just anti-FUD).
The charges
In an interview [http://www.devx.com/Java/Article/28125/0/page/1] with DevX, Gosling made some comments, which, to anyone already sceptical or ignorant of OSS, give a completely false impression.
"It's often difficult to get a good picture from the open source community of what they actually object to in what we're doing. In what way could we be more open? Since day zero, 10 years ago, all of our sources have been open and available, very similar to how many projects in open source work."
Later, he adds,
"We've got several thousand man-years of engineering in [Java], and we hear very strongly that if this thing turned into an open source project - where just any old person could check in stuff - they'd all freak. They'd all go screaming into the hills."
And in a subsequent interview [http://www2.vnunet.com/lite/News/1163182] on Vnunet:
"I understand why [the OSS community] would like it to be different. From our point of view that would actually be more destructive than helpful. It boils down to forking: they believe that the ability to fork is an absolutely critical right."
Let's be clear here - these are Gosling's opinions, not those necessarily of Sun. Gosling and Stallman famously had a fracas [http://www.free-soft.org/gpl_history/] over Emacs which became the impetus for the GPL, so perhaps it's not so strange that Gosling has anti-OSS sentiments, and that Stallman has all guns blazing [http://www.gnu.org/philosophy/java-trap.html] at Java. However, I've seen them echoed within various quarters of the Java community itself, and so it's a worthwhile cause to have a closer look, I think.
Who wants a free cup of coffee?
From an ideological perspective, Richard Stallman is clearly at the front of the queue here! Free to see the source code; free to modify the source code; free to redistribute the code. It's a freedom of speech thing really! OSS isn't necessarily about giving products away for free (i.e., without payment). You can still charge for it, but your source will be visible to the end-user (should they care to look). The Java platform is free as in beer, i.e., you don't have to pay. You can look at the source. You can modify and recompile. You can't freely redistribute modified Sun code. Tut tut: hell hath no fury like a RMS scorned [http://software.newsforge.com/software/05/05/16/1358227.shtml?tid=152&tid=150&tid=89&tid=93&tid=132]...
From my experience, people don't like open source software because they can exercise the freedom of hacking with source code. They like it because it tends to deliver stable products; because it innovates; because it responds quickly to bugs and security issues; because it does the boring stuff that no-one else wants to do!
I've been fortunate to have an excellent contact regarding the Java/OSS issue in the shape of Dalibor Topic [http://www.advogato.org/person/robilad/]. He's unashamedly pro-free software and is the lead developer of Kaffe, contributor to GNU Classpath and Harmony participant. A tad biased one expects, but he always delivers decent explanations of the current situation - starting with Apache's motives,
"Apache Software Foundation, an organisation that's been quite successful at writing, maintaining and encouraging donations of Free Software written in the Java programming language eventually started thinking that a full J2SE implementation might be a good thing to have under Apache's umbrella as well, beside a huge chunk of the stack above it."
I couldn't agree more! The ASF have released some fantastic Java libraries that add tremendous value to the platform. Think about Ant, Log4j, Lucene, Struts, all the XML projects, and then there's Jakarta: Commons, POI, Tomcat, Velocity, Tapestry and so on. It's not just ASF who want an open J2SE to complete their stack, there is the wider free software community who need it. Dalibor notes:
"These days, there is an almost full Free Software stack, going from the Linux kernel, to the supporting GNU libraries from one side, and going from certified, compatible enterprise software development and deployment environments and their supporting libraries from the other side, like JBoss or JOnAS. The only remaining non-free card in that software stack is a fully compatible Free Software runtime for programs and libraries written in the Java programming language."
But I just made you a cuppa
There even seems to be some dissent within the OSS community itself. This is because OSS is itself a broad term and encapsulates a whole spectrum of ideologies. You don't have to look far before you find a complaints that Apache appear to be duplicating the efforts of GNU Classpath [http://www.gnu.org/software/classpath/classpath.html] and VMs like Kaffe [http://www.kaffe.org] or GCJ [http://gcc.gnu.org/java/]. This isn't the case. The Harmony team want to reuse as much of the pre-existing components as possible (you would be foolish not to!) The issue is that there is a slight conflict between the GPL license and the Apache license. The difference essentially boils down to the fact that redistributed GPL code must preserve the GPL license (and thus remain Free) where as Apache lets you redistribute under your own license. But, Classpath has an 'exception' clause similar to that found in libgcc/libg++ which permits linkage in binary form under your own license. This means that Harmony could work by having Classpath as a binary dependency, thereby avoiding the reimplementation of the class libraries. Likewise there's already talk of using JCVM [http://jcvm.sourceforge.net/] as a base for the VM. So, reuse is clearly on the agenda and Harmony is seeking all Apache friendly resources to evaluate their potential. Any shortcomings will of course have to be met by the Harmony developers and may require implementation of that component from scratch.
Forkin' hell
The biggest argument for resisting the opening of Java is that it permits forks of the platform that would lead to incompatible versions all competing against each other. The idea that all open source advocates want to do is fork everything is a slight exaggeration. Still, this is a very real concern that should be considered carefully. The example given is to think about all the hassle you have making sure your web page looks correct on all the mainstream browsers. Even closer to home was the controversy of Microsoft's non-standard JVM.
I personally don't think there will be many instances of a fully forked Java platform. It's pretty darn big! And I don't think any one wants to see a fragmented platform. What I think would happen is what I call 'micro-forks': stripped down versions that are designed for specific purposes. I also imagine you'd see the JVM ported to several other platforms that are not on Sun's radar at the moment. Dalibor speaks of Kaffe's success on reaching new platforms:
"Kaffe is one of the most widely ported pieces of runtime software around. In total, it has been ported to more than 70 platforms, ranging from good old x86 GNU/Linux to WindowsCE and PlayStation 2. There is a lot of interest on niche platforms in having ready access to Free Software written in the Java programming language, in particular if the platform in question does not have enough marketing value for some large corporation to step in and fund the porting and certification effort of a non-free runtime."
Sun already has a method to ensure the fragmentation of Java is avoided with it's JCK [https://jck.dev.java.net/] compatibility test suite. Since anyone is free to write their own Java compiler or runtime, Sun wanted a system that gives you the seal of approval, in that your implementation conforms to the specifications. It contains comprehensive testing of all aspects of the platform and at last count the number of tests it contained was around one-hundred-billion-trillion, times infinity, plus 1, plus tax. So, it's quite thorough and without it, Java's lawyers will hunt you down if you try and stick the 'Java' badge on your implementation. Dalibor pointed out to me:
"The major argument against breaking the platform is that on the broken platform the wealth of good software written in the Java programming language will not work, so it would be a pointless exercise now, after 10 years of software development. No one would switch to something broken when they can use the real, working thing.
"One must also note that official and unofficial extensions to the Java programming language, like support for generics, have existed already for years without the platform breaking apart. The 'everything will break and collapse' argument has been thoroughly refuted by the history of the platform."
A typical real world example I have come across: Java applications are often bundled with their own local copy of a JVM (to simplify deployment, as opposed to relying on the user installing the required version). Say I spot a bug in a core class that's causing me a head-ache. I look at the source and notice it's a really trivial error. I correct it and resubmit to Sun. If it gets approved, I then I could be waiting up to 18 months for the next official before I can get hold of a JRE that fixes the bug which I can legally deploy to customers. I can't distribute my fixed version of the class. Therefore, depending on the bug, I have to sub-class and fix by over-riding affected methods. A lot of work for what was a simple fix (cue cries from the Aspect Oriented Programming crowd). If it's a JVM bug, then you've no chance. There are also developers who simply want to remove packages that are not needed by their application - no source changes at all, but even that is not permitted. Would this really be a problem?
Java, Page 2/2
Get off my land!
The very notion that an open source project is automatically open to anyone to mess around with is laughable. Imagine I have an OSS project called CupOfTea. If you get hold of the source, you only have a copy of my source. You can mess that up as much as you like, but it will never affect CupOfTea. Now, OSS projects tend to promote the idea of gathering a community of programmers, but it's not the law! I have control of CupOfTea's source, and if I choose to, I can grant someone else access to modify the code, but it's very rare to see a project which allows an untrusted person access to the main branch.
For any large OSS project, structures and policies become part of the development process to ensure only worthwhile and tested submissions are committed to the development source, and meritocracies typically determine who gets access to the source. Sun would be no different when it comes to managing their Java source. If "any old person could check in stuff" into Java (if it were ever open sourced) then that's just bad management, which Sun simply wouldn't let happen: it's not as if they're open source virgins (think OpenOffice and OpenSolaris). Basically, it's a myth and Gosling should know better than to spread this one around.
Keep the change
Only the most eternal optimist is expecting Java to open their platform in a OSI compatible fashion. The free software world has accepted over the last 10 years that it's not going to happen. Heck, that's all part of free speech too, by the way. It's not that OSS communities expect a free lunch [http://www.gnu.org/philosophy/shouldbefree.html] here. Sun has invested so much in the platform and is undoubtedly the reason why it's reached such success in a relatively short time. They just want an open Java platform that can happily co-exist with their open OSes. Sun's Java license [http://java.sun.com/j2se/1.5.0/jdk-1_5_0_03-license.txt] has a nasty clause under section B regarding the distribution of the JDK (and similarly for the JRE):
"...(iii) you do not distribute additional software intended to replace any component(s) of the Software,"
The interpretation [http://www.debian.org/doc/manuals/debian-java-faq/ch5.html#s-license-concerns] is as follows: say I'm about to release MyOpenOS and am deciding which packages to bundle, if I put the Java binaries on it, I can't then have alternatives like the Jikes compiler, GNU Classpath, Kaffe VM, etc., bundled too. Open OSes won't accept this clause as they believe that users have the freedom to pick alternatives if they wish - and therefore Sun's JRE/JDK doesn't often get bundled. This is a shame because installing the official JRE/JDK on Linux isn't as user-friendly as its Windows equivalent. It would have been an advantage, therefore, for Sun to leave it up to the OS maintainers to do the work to ensure easier deployment of Java on open platforms.
This is why there has been so much effort by the OSS community over the years. Sun won't open up Java, so the OSS guys will do it for them! Gosling may exclaim that Java is "open" enough, yet once again this shows a lack of understanding of what free software is about. Dalibor makes a solid case:
"I find Sun Microsystems's marketing staff's desperate attempts funny, to try to rub off some the magic Open Source pixie dust of great street-credibility and coolness by pretending that their non-free implementations' licenses are just as good as Open Source ones. I think it would be equivalently futile if someone tried to confuse developers and users about the fact that Kaffe is not Java(TM), in the same sense that it is not Pepsi(TM) or Coca Cola(TM), or that GNU is not Unix(TM).
"When Kaffe eventually passes the official compatibility test suites from the JCP, then it (or a suitable fork of it) may get branded with the Java(TM) label. If Kaffe or Apache Harmony were trying to rub off some magic from Sun Microsystems's Java trademark before they meet the rules for the use of that trademark, such behaviour would be very misleading and rude towards Sun Microsystems. Proprietary software marketing efforts trying to rub off the good Open Source image without the marketed software meeting the criteria to be called Open Source, are an equivalently futile and funny attempt to mislead Open Source developers and users."
Allow me to take a small diversion... OpenSolaris has been taking its time because it had to work around 3rd party licensing issues. I expected similar constraints in Java that could hinder an open implementation. For anyone with more than their fair share of spare time, you can have a look at the 3rd Party Readme [http://java.sun.com/j2se/1.5.0/j2se-1_5_0-thirdpartyreadme.txt] that accompanies the J2SE platform. I couldn't see much in the form of propriety licenses, but you'll quickly find that Java benefits from a number of open source projects, including:
1. Apache Xerces [http://xml.apache.org/xerces2-j] (XML parser)
2. Apache Xalan J2 [http://xml.apache.org/xalan-j/] (XSLT processor)
3. SAX [http://www.saxproject.org/] (XML API)
4. Nullsoft NSIS [http://nsis.sourceforge.net/] (Windows installer)
5. IBM ICU4J [http://icu.sourceforge.net/] (Unicode support, software internationalisation and globalisation libraries)
6. IAIK PKCS#11 Wrapper [http://jce.iaik.tugraz.at/products/14_PKCS11_Wrapper/index.php] (Cryptographic Token Interface Standard implementation)
7. CUPS API [http://www.cups.org] (*N*X printing APIs)
8. MESA [http://www.mesa3d.org/] (OpenGL library)
9. Apache BCEL [http://jakarta.apache.org/bcel/] (Byte Code Engineering Library)
10. Apache Jakarta Regexp [http://jakarta.apache.org/regexp/index.html] (regular expression package)
11. JLex [http://www.cs.princeton.edu/~appel/modern/java/CUP/CUP Parser Generator (A parser generator like YACC)
12.
13. Crytpix [http://www.cryptix.org/] (Crypto package)
It's not many in the grand scheme of things, although the XML related projects are very key components to the platform. I wouldn't be surprised to hear if Java engineers have helped many of these projects since utilising them - fixing bugs or extending features, and re-contributing back (although I don't know for sure). Yet, it goes to show how commercial projects continually benefit from open source projects - even Java - so it can't be that bad, eh?
Drinking from the same cup
What gets me is that the Java crew know that many enterprises are scared of open source and hence are likely to "run for the hills" at the thought of Java being opened. However, instead of merely vocalising these fears, how about some education? You see, just like when someone moans at me and says "isn't Java slow?", I don't sit back and let them dwell in their ignorance, I'll explain why this is an untruth. It would have been nice that if in Sun's consultation with their customers, instead of playing on the fears of enterprises, and hence helping to reinforce their fear-based closed-source stance, they clarify things, "No, Mr BigCustomer, open source isn't what you think, it can help with A, B, and C, but it isn't helpful in X, Y, Z. Therefore, we've decided to keep Java closed, whilst doing what we can to promote a community of volunteer contributors..." But it doesn't - it sends out mixed messages. Sun has just recently responded to customer demands with the new JIUL license [http://www.java.net/jiul.csp] to allow them to modify the JRE within an organisation. Dalibor's observation was:
"It is fascinating to see how Sun Microsystems' customers, the same people who according to some would run straight to the hills on mention of Open Source, are at the same time apparently asking for freedoms to modify Sun Microsystems' implementation and distribute those modifications. The same freedoms that are granted and protected by Open Source software licenses."
The thing is, you can't deny that with open source, you open the door to forks. Yet the assumption that they are all bad is perhaps unfair. With the Linux kernel for example, you see several high-profile forks, which are essentially kept in sync with Linus's release, and have a set of patches on top that do additional things like tightening up security, performance boosts, etc. People don't actually want to deviate far from the main branch, just the freedom to tweak if they so feel like. This experimentation helps because successful advances can be reincorporated back to the main branch if they prove robust. Dalibor speaks of his experience:
"Kaffe has been forked a lot of times for specific purposes, and those forks have been great for the development of the project. They lead to fresh code and insight from developers and researchers taking it to new tasks like isolation, single system image, real-time or runtime environments for handheld platforms. Those different research goals could have been problematic to manage within a single project that users and developers expect to build and run for each release on more than a dozen of rapidly evolving platforms. Therefore researchers are encouraged to fork Kaffe if they have some really specific research needs, and, if they want, send patches back when they are done. By having people fork off a stable release, and integrating their work back later when it is ready, the Kaffe project is able to both sustain a fast rate of progress and gradually incorporate exciting new code from projects like JanosVM, Kangaroo or Jessica."
I personally don't think Sun is terribly worried about what the OSS community would do with Java - I think they're worried [http://www.almaer.com/blog/archives/000939.html] what a certain three-letter-acronym with a fondness for the colour blue would do with it.
Summary
So, let's recap,
1. OSS doesn't mean that Sun loses control of its Java platform (NB Sun never had control of the clean-room implementations in the first place).
2. OSS doesn't mean that any one can mess with the source - you copy it and mess with your own.
3. OSS doesn't mean forking. If derivatives do come, then they don't twist anyone's arm to force them to use it. There must be a compelling reason for it. Therefore, enterprise customers can stick with Sun - whilst the OSS boys play with their toys - and needn't go running to the hills after all.
It occurs to me that with increasing pressure from .Net, Sun will have to be looking over its shoulder to ensure it stays ahead of MS and its seemingly bottom-less pockets. I want to see Java succeed well in to the future and I personally see leveraging the energies of the OSS community will give it greater strength. You could submit patches back to Java, if you're happy with the license and faxed their form back! (NB, if you ever sign up, or even look at Java's source, you are no longer eligible to contribute to OSS Java projects as you are now contaminated!) There will be many who want to contribute but won't until it's under an OSI approved license. In the meantime, I simply hope that the sceptics have a better understanding of what the OSS community is about. Regardless of whether you're pro- or anti-OSS, at least you can make a more informed decision now. I'll finish with an optimistic view of the future from Dalibor:
"In the long run, though, GNU Classpath, gcj and Kaffe will probably pass the official test suites eventually, lead to a whole set of related Free Software runtimes passing those compatibility tests, and in turn make bytecode runtime environments as much as a commodity as GCC and g++ did it for the C and C++ development tools.
"If anyone can make the 'write once, run anywhere' slogan true, then it is a set of compatible Free Software runtimes for all occasions and environments."
About the author:
Andrew Roberts [http://www.comp.leeds.ac.uk/andyr/] is a computer science graduate from the University of Leeds, UK. He remained at Leeds to study further towards a PhD in Natural Language Processing. He has been using Linux for almost 8 years, and Java has been his language of choice for advanced language processing and machine learning during the last three years.
(http://www.osnews.com/printer.php?news_id=10806)
Java, Page 1/2
Whilst obviously aiming to be as objective as possible, I think it fair to let you know my leanings. I'm a big OSS fan. I've been using various forms of the GNU/Linux platform for around 8 years. I'm not a purist though: I will use propriety products if it does the job. Proof of this is that I am also a big Java fan. I started learning it around 5 years ago, although it's the last 3 years or so that it's been my main language. I honestly don't have an issue with the Java team, or Sun in general about their decisions. I don't always agree with their approach, specifically their licenses, but I don't mean to be anti-Sun, even if it should appear that way in this article (just anti-FUD).
The charges
In an interview [http://www.devx.com/Java/Article/28125/0/page/1] with DevX, Gosling made some comments, which, to anyone already sceptical or ignorant of OSS, give a completely false impression.
"It's often difficult to get a good picture from the open source community of what they actually object to in what we're doing. In what way could we be more open? Since day zero, 10 years ago, all of our sources have been open and available, very similar to how many projects in open source work."
Later, he adds,
"We've got several thousand man-years of engineering in [Java], and we hear very strongly that if this thing turned into an open source project - where just any old person could check in stuff - they'd all freak. They'd all go screaming into the hills."
And in a subsequent interview [http://www2.vnunet.com/lite/News/1163182] on Vnunet:
"I understand why [the OSS community] would like it to be different. From our point of view that would actually be more destructive than helpful. It boils down to forking: they believe that the ability to fork is an absolutely critical right."
Let's be clear here - these are Gosling's opinions, not those necessarily of Sun. Gosling and Stallman famously had a fracas [http://www.free-soft.org/gpl_history/] over Emacs which became the impetus for the GPL, so perhaps it's not so strange that Gosling has anti-OSS sentiments, and that Stallman has all guns blazing [http://www.gnu.org/philosophy/java-trap.html] at Java. However, I've seen them echoed within various quarters of the Java community itself, and so it's a worthwhile cause to have a closer look, I think.
Who wants a free cup of coffee?
From an ideological perspective, Richard Stallman is clearly at the front of the queue here! Free to see the source code; free to modify the source code; free to redistribute the code. It's a freedom of speech thing really! OSS isn't necessarily about giving products away for free (i.e., without payment). You can still charge for it, but your source will be visible to the end-user (should they care to look). The Java platform is free as in beer, i.e., you don't have to pay. You can look at the source. You can modify and recompile. You can't freely redistribute modified Sun code. Tut tut: hell hath no fury like a RMS scorned [http://software.newsforge.com/software/05/05/16/1358227.shtml?tid=152&tid=150&tid=89&tid=93&tid=132]...
From my experience, people don't like open source software because they can exercise the freedom of hacking with source code. They like it because it tends to deliver stable products; because it innovates; because it responds quickly to bugs and security issues; because it does the boring stuff that no-one else wants to do!
I've been fortunate to have an excellent contact regarding the Java/OSS issue in the shape of Dalibor Topic [http://www.advogato.org/person/robilad/]. He's unashamedly pro-free software and is the lead developer of Kaffe, contributor to GNU Classpath and Harmony participant. A tad biased one expects, but he always delivers decent explanations of the current situation - starting with Apache's motives,
"Apache Software Foundation, an organisation that's been quite successful at writing, maintaining and encouraging donations of Free Software written in the Java programming language eventually started thinking that a full J2SE implementation might be a good thing to have under Apache's umbrella as well, beside a huge chunk of the stack above it."
I couldn't agree more! The ASF have released some fantastic Java libraries that add tremendous value to the platform. Think about Ant, Log4j, Lucene, Struts, all the XML projects, and then there's Jakarta: Commons, POI, Tomcat, Velocity, Tapestry and so on. It's not just ASF who want an open J2SE to complete their stack, there is the wider free software community who need it. Dalibor notes:
"These days, there is an almost full Free Software stack, going from the Linux kernel, to the supporting GNU libraries from one side, and going from certified, compatible enterprise software development and deployment environments and their supporting libraries from the other side, like JBoss or JOnAS. The only remaining non-free card in that software stack is a fully compatible Free Software runtime for programs and libraries written in the Java programming language."
But I just made you a cuppa
There even seems to be some dissent within the OSS community itself. This is because OSS is itself a broad term and encapsulates a whole spectrum of ideologies. You don't have to look far before you find a complaints that Apache appear to be duplicating the efforts of GNU Classpath [http://www.gnu.org/software/classpath/classpath.html] and VMs like Kaffe [http://www.kaffe.org] or GCJ [http://gcc.gnu.org/java/]. This isn't the case. The Harmony team want to reuse as much of the pre-existing components as possible (you would be foolish not to!) The issue is that there is a slight conflict between the GPL license and the Apache license. The difference essentially boils down to the fact that redistributed GPL code must preserve the GPL license (and thus remain Free) where as Apache lets you redistribute under your own license. But, Classpath has an 'exception' clause similar to that found in libgcc/libg++ which permits linkage in binary form under your own license. This means that Harmony could work by having Classpath as a binary dependency, thereby avoiding the reimplementation of the class libraries. Likewise there's already talk of using JCVM [http://jcvm.sourceforge.net/] as a base for the VM. So, reuse is clearly on the agenda and Harmony is seeking all Apache friendly resources to evaluate their potential. Any shortcomings will of course have to be met by the Harmony developers and may require implementation of that component from scratch.
Forkin' hell
The biggest argument for resisting the opening of Java is that it permits forks of the platform that would lead to incompatible versions all competing against each other. The idea that all open source advocates want to do is fork everything is a slight exaggeration. Still, this is a very real concern that should be considered carefully. The example given is to think about all the hassle you have making sure your web page looks correct on all the mainstream browsers. Even closer to home was the controversy of Microsoft's non-standard JVM.
I personally don't think there will be many instances of a fully forked Java platform. It's pretty darn big! And I don't think any one wants to see a fragmented platform. What I think would happen is what I call 'micro-forks': stripped down versions that are designed for specific purposes. I also imagine you'd see the JVM ported to several other platforms that are not on Sun's radar at the moment. Dalibor speaks of Kaffe's success on reaching new platforms:
"Kaffe is one of the most widely ported pieces of runtime software around. In total, it has been ported to more than 70 platforms, ranging from good old x86 GNU/Linux to WindowsCE and PlayStation 2. There is a lot of interest on niche platforms in having ready access to Free Software written in the Java programming language, in particular if the platform in question does not have enough marketing value for some large corporation to step in and fund the porting and certification effort of a non-free runtime."
Sun already has a method to ensure the fragmentation of Java is avoided with it's JCK [https://jck.dev.java.net/] compatibility test suite. Since anyone is free to write their own Java compiler or runtime, Sun wanted a system that gives you the seal of approval, in that your implementation conforms to the specifications. It contains comprehensive testing of all aspects of the platform and at last count the number of tests it contained was around one-hundred-billion-trillion, times infinity, plus 1, plus tax. So, it's quite thorough and without it, Java's lawyers will hunt you down if you try and stick the 'Java' badge on your implementation. Dalibor pointed out to me:
"The major argument against breaking the platform is that on the broken platform the wealth of good software written in the Java programming language will not work, so it would be a pointless exercise now, after 10 years of software development. No one would switch to something broken when they can use the real, working thing.
"One must also note that official and unofficial extensions to the Java programming language, like support for generics, have existed already for years without the platform breaking apart. The 'everything will break and collapse' argument has been thoroughly refuted by the history of the platform."
A typical real world example I have come across: Java applications are often bundled with their own local copy of a JVM (to simplify deployment, as opposed to relying on the user installing the required version). Say I spot a bug in a core class that's causing me a head-ache. I look at the source and notice it's a really trivial error. I correct it and resubmit to Sun. If it gets approved, I then I could be waiting up to 18 months for the next official before I can get hold of a JRE that fixes the bug which I can legally deploy to customers. I can't distribute my fixed version of the class. Therefore, depending on the bug, I have to sub-class and fix by over-riding affected methods. A lot of work for what was a simple fix (cue cries from the Aspect Oriented Programming crowd). If it's a JVM bug, then you've no chance. There are also developers who simply want to remove packages that are not needed by their application - no source changes at all, but even that is not permitted. Would this really be a problem?
Java, Page 2/2
Get off my land!
The very notion that an open source project is automatically open to anyone to mess around with is laughable. Imagine I have an OSS project called CupOfTea. If you get hold of the source, you only have a copy of my source. You can mess that up as much as you like, but it will never affect CupOfTea. Now, OSS projects tend to promote the idea of gathering a community of programmers, but it's not the law! I have control of CupOfTea's source, and if I choose to, I can grant someone else access to modify the code, but it's very rare to see a project which allows an untrusted person access to the main branch.
For any large OSS project, structures and policies become part of the development process to ensure only worthwhile and tested submissions are committed to the development source, and meritocracies typically determine who gets access to the source. Sun would be no different when it comes to managing their Java source. If "any old person could check in stuff" into Java (if it were ever open sourced) then that's just bad management, which Sun simply wouldn't let happen: it's not as if they're open source virgins (think OpenOffice and OpenSolaris). Basically, it's a myth and Gosling should know better than to spread this one around.
Keep the change
Only the most eternal optimist is expecting Java to open their platform in a OSI compatible fashion. The free software world has accepted over the last 10 years that it's not going to happen. Heck, that's all part of free speech too, by the way. It's not that OSS communities expect a free lunch [http://www.gnu.org/philosophy/shouldbefree.html] here. Sun has invested so much in the platform and is undoubtedly the reason why it's reached such success in a relatively short time. They just want an open Java platform that can happily co-exist with their open OSes. Sun's Java license [http://java.sun.com/j2se/1.5.0/jdk-1_5_0_03-license.txt] has a nasty clause under section B regarding the distribution of the JDK (and similarly for the JRE):
"...(iii) you do not distribute additional software intended to replace any component(s) of the Software,"
The interpretation [http://www.debian.org/doc/manuals/debian-java-faq/ch5.html#s-license-concerns] is as follows: say I'm about to release MyOpenOS and am deciding which packages to bundle, if I put the Java binaries on it, I can't then have alternatives like the Jikes compiler, GNU Classpath, Kaffe VM, etc., bundled too. Open OSes won't accept this clause as they believe that users have the freedom to pick alternatives if they wish - and therefore Sun's JRE/JDK doesn't often get bundled. This is a shame because installing the official JRE/JDK on Linux isn't as user-friendly as its Windows equivalent. It would have been an advantage, therefore, for Sun to leave it up to the OS maintainers to do the work to ensure easier deployment of Java on open platforms.
This is why there has been so much effort by the OSS community over the years. Sun won't open up Java, so the OSS guys will do it for them! Gosling may exclaim that Java is "open" enough, yet once again this shows a lack of understanding of what free software is about. Dalibor makes a solid case:
"I find Sun Microsystems's marketing staff's desperate attempts funny, to try to rub off some the magic Open Source pixie dust of great street-credibility and coolness by pretending that their non-free implementations' licenses are just as good as Open Source ones. I think it would be equivalently futile if someone tried to confuse developers and users about the fact that Kaffe is not Java(TM), in the same sense that it is not Pepsi(TM) or Coca Cola(TM), or that GNU is not Unix(TM).
"When Kaffe eventually passes the official compatibility test suites from the JCP, then it (or a suitable fork of it) may get branded with the Java(TM) label. If Kaffe or Apache Harmony were trying to rub off some magic from Sun Microsystems's Java trademark before they meet the rules for the use of that trademark, such behaviour would be very misleading and rude towards Sun Microsystems. Proprietary software marketing efforts trying to rub off the good Open Source image without the marketed software meeting the criteria to be called Open Source, are an equivalently futile and funny attempt to mislead Open Source developers and users."
Allow me to take a small diversion... OpenSolaris has been taking its time because it had to work around 3rd party licensing issues. I expected similar constraints in Java that could hinder an open implementation. For anyone with more than their fair share of spare time, you can have a look at the 3rd Party Readme [http://java.sun.com/j2se/1.5.0/j2se-1_5_0-thirdpartyreadme.txt] that accompanies the J2SE platform. I couldn't see much in the form of propriety licenses, but you'll quickly find that Java benefits from a number of open source projects, including:
1. Apache Xerces [http://xml.apache.org/xerces2-j] (XML parser)
2. Apache Xalan J2 [http://xml.apache.org/xalan-j/] (XSLT processor)
3. SAX [http://www.saxproject.org/] (XML API)
4. Nullsoft NSIS [http://nsis.sourceforge.net/] (Windows installer)
5. IBM ICU4J [http://icu.sourceforge.net/] (Unicode support, software internationalisation and globalisation libraries)
6. IAIK PKCS#11 Wrapper [http://jce.iaik.tugraz.at/products/14_PKCS11_Wrapper/index.php] (Cryptographic Token Interface Standard implementation)
7. CUPS API [http://www.cups.org] (*N*X printing APIs)
8. MESA [http://www.mesa3d.org/] (OpenGL library)
9. Apache BCEL [http://jakarta.apache.org/bcel/] (Byte Code Engineering Library)
10. Apache Jakarta Regexp [http://jakarta.apache.org/regexp/index.html] (regular expression package)
11. JLex [http://www.cs.princeton.edu/~appel/modern/java/CUP/CUP Parser Generator (A parser generator like YACC)
12.
13. Crytpix [http://www.cryptix.org/] (Crypto package)
It's not many in the grand scheme of things, although the XML related projects are very key components to the platform. I wouldn't be surprised to hear if Java engineers have helped many of these projects since utilising them - fixing bugs or extending features, and re-contributing back (although I don't know for sure). Yet, it goes to show how commercial projects continually benefit from open source projects - even Java - so it can't be that bad, eh?
Drinking from the same cup
What gets me is that the Java crew know that many enterprises are scared of open source and hence are likely to "run for the hills" at the thought of Java being opened. However, instead of merely vocalising these fears, how about some education? You see, just like when someone moans at me and says "isn't Java slow?", I don't sit back and let them dwell in their ignorance, I'll explain why this is an untruth. It would have been nice that if in Sun's consultation with their customers, instead of playing on the fears of enterprises, and hence helping to reinforce their fear-based closed-source stance, they clarify things, "No, Mr BigCustomer, open source isn't what you think, it can help with A, B, and C, but it isn't helpful in X, Y, Z. Therefore, we've decided to keep Java closed, whilst doing what we can to promote a community of volunteer contributors..." But it doesn't - it sends out mixed messages. Sun has just recently responded to customer demands with the new JIUL license [http://www.java.net/jiul.csp] to allow them to modify the JRE within an organisation. Dalibor's observation was:
"It is fascinating to see how Sun Microsystems' customers, the same people who according to some would run straight to the hills on mention of Open Source, are at the same time apparently asking for freedoms to modify Sun Microsystems' implementation and distribute those modifications. The same freedoms that are granted and protected by Open Source software licenses."
The thing is, you can't deny that with open source, you open the door to forks. Yet the assumption that they are all bad is perhaps unfair. With the Linux kernel for example, you see several high-profile forks, which are essentially kept in sync with Linus's release, and have a set of patches on top that do additional things like tightening up security, performance boosts, etc. People don't actually want to deviate far from the main branch, just the freedom to tweak if they so feel like. This experimentation helps because successful advances can be reincorporated back to the main branch if they prove robust. Dalibor speaks of his experience:
"Kaffe has been forked a lot of times for specific purposes, and those forks have been great for the development of the project. They lead to fresh code and insight from developers and researchers taking it to new tasks like isolation, single system image, real-time or runtime environments for handheld platforms. Those different research goals could have been problematic to manage within a single project that users and developers expect to build and run for each release on more than a dozen of rapidly evolving platforms. Therefore researchers are encouraged to fork Kaffe if they have some really specific research needs, and, if they want, send patches back when they are done. By having people fork off a stable release, and integrating their work back later when it is ready, the Kaffe project is able to both sustain a fast rate of progress and gradually incorporate exciting new code from projects like JanosVM, Kangaroo or Jessica."
I personally don't think Sun is terribly worried about what the OSS community would do with Java - I think they're worried [http://www.almaer.com/blog/archives/000939.html] what a certain three-letter-acronym with a fondness for the colour blue would do with it.
Summary
So, let's recap,
1. OSS doesn't mean that Sun loses control of its Java platform (NB Sun never had control of the clean-room implementations in the first place).
2. OSS doesn't mean that any one can mess with the source - you copy it and mess with your own.
3. OSS doesn't mean forking. If derivatives do come, then they don't twist anyone's arm to force them to use it. There must be a compelling reason for it. Therefore, enterprise customers can stick with Sun - whilst the OSS boys play with their toys - and needn't go running to the hills after all.
It occurs to me that with increasing pressure from .Net, Sun will have to be looking over its shoulder to ensure it stays ahead of MS and its seemingly bottom-less pockets. I want to see Java succeed well in to the future and I personally see leveraging the energies of the OSS community will give it greater strength. You could submit patches back to Java, if you're happy with the license and faxed their form back! (NB, if you ever sign up, or even look at Java's source, you are no longer eligible to contribute to OSS Java projects as you are now contaminated!) There will be many who want to contribute but won't until it's under an OSI approved license. In the meantime, I simply hope that the sceptics have a better understanding of what the OSS community is about. Regardless of whether you're pro- or anti-OSS, at least you can make a more informed decision now. I'll finish with an optimistic view of the future from Dalibor:
"In the long run, though, GNU Classpath, gcj and Kaffe will probably pass the official test suites eventually, lead to a whole set of related Free Software runtimes passing those compatibility tests, and in turn make bytecode runtime environments as much as a commodity as GCC and g++ did it for the C and C++ development tools.
"If anyone can make the 'write once, run anywhere' slogan true, then it is a set of compatible Free Software runtimes for all occasions and environments."
About the author:
Andrew Roberts [http://www.comp.leeds.ac.uk/andyr/] is a computer science graduate from the University of Leeds, UK. He remained at Leeds to study further towards a PhD in Natural Language Processing. He has been using Linux for almost 8 years, and Java has been his language of choice for advanced language processing and machine learning during the last three years.
(http://www.osnews.com/printer.php?news_id=10806)
Wednesday, April 05, 2006
Oracle's SPFILE by Amar Kumar Padhi
Oracle requires an initialization file to define the attributes and characteristics of the starting instance and the connecting sessions there of. We are aware of the Initialization parameter file (also referred as init.ora file or PFILE). This file holds the setup parameters that define the attribute of the instance that is being started. Administrators can control, tune and optimize an instance by setting and modifying the initialization parameters in this file.
Some parameters can be dynamically modified to affect the present instance, while others require the instance to be brought down so that changes can take affect. This remains the same when using PFILE or SPFILE. A simple search on the net will reveal a lot of information regarding PFILE and SPFILE.
Parameter files are by default situated in $ORACLE_HOME/dbs (on UNIX) or %ORACLE_HOME%\database (on Windows) directory.
SPFILE
SPFILE stands for Server Parameter File. It is an extension of the initialization parameter storage mechanism, which allows some additional advantages as compared to the simple text based init.ora file. This feature aims at advancing towards Oracle's self-tuning capabilities. As the name states, the file is present on the server side and is not required on the client to start the instance.
*
It is a binary file and the use of editors to modify it is not supported. The only way of changing parameter values is by using the ALTER SYSTEM SET/RESET command.
*
If using the PFILE option, parameter changes done with the ALTER SYSTEM command need to be manually changed in the init.ora file to reflect the changes on future startups. With SPFILE, the ALTER SYSTEM command can update the binary file as well. This allows the changes to be persistent across startups.
*
Since it is binary, it is prone to becoming corrupt if things go wrong. As a backup strategy, create copies of the SPFILE and convert it to a text-based PFILE for safe keeping.
*
The ISSYS_MODIFIABLE column in V$PARAMETER tells us whether the parameters are static or dynamic. Static parameters require the instance to be restarted while dynamic parameters can take effect immediately upon being changed.
SQL> select distinct issys_modifiable from v$parameter;
ISSYS_MODIFIABLE
---------------------------
DEFERRED
FALSE
IMMEDIATE
If the ISSYS_MODIFIABLE value is set to FALSE for a parameter, it means that the parameter cannot change its value in the lifetime of the instance; the database needs to be restarted for changes to take effect. A parameter set to IMMEDATE value means that it is dynamic and can be set to change the present active instance as well as future database restarts. A parameter set to DEFERRED is also dynamic, but changes only affect subsequent sessions, currently active sessions will not be affected and retain the old parameter value.
*
The PFILE is required from the client from where the instance is being started. The SPFILE is not required to be from the client from where the instance is started. This comes in handy when we are trying to start the database remotely.
*
If you have a standby database, the primary database parameter changes are not propagated to the standby. This needs to be done manually and SPFILE does not aid in this.
*
If no SPFILE exists and one needs to be created, Oracle requires that the instance should be started at least once with the PFILE and then the SPFILE created. SPFILE is the default mode in new releases.
*
In a multi-instance Real Application cluster system, a single copy of the SPFILE can be used for all instances. The SPFILE maintains different format styles to support both the common values for all instances as well as specific values for individual instances.
*
The default behavior of the STARTUP command is changed to look for an SPFILE first, when no PFILE option is explicitly specified.
*
The contents of SPFILE can be obtained from V$SPPARAMETER view. The parameters having ISSPECIFIED column set to TRUE are the ones present in the binary file.
*
You only need to be connected as SYSDBA/SYSOPER to create the SPFILE or PFILE. The database need not be started. This option is useful in case the SPFILE has been corrupted and you need to rebuild it from a PFILE.
Which SPFILE on startup
If you have multiple SPFILEs, it will be confusing to identify which file is linked to which instance. By default, the SPFILE name is spfile.ora. This information can be identified by looking at the below logs/views:
1. The alert log can be looked at. If the log shows the SPFILE parameter in "System parameters with non-default value" section, then it is clear that the instance was started with the pfile internally calling the SPFILE using the parameter.
2. Check the SPFILE parameter value in V$PARAMETER view.
ALTER SYSTEM command for SPFILE
SPFILE can be modified by using the ALTER SYSTEM command. This command allows us to set and reset the parameter values.
alter system set=
scope=
comment=<'comments'>
deferred
sid=
The SCOPE clause of the command decides how the changes will take effect. This option can have the following values:
MEMORY - changes are active for the current instance only and are lost on restart.
SPFILE - changes are stored in the SPFILE and are activated on the next startup, the presently active instance is not affected. Static parameters need this option to change their values.
BOTH - changes are effective immediately for the present instance and are stored in SPFILE for future startups. This is the default.
COMMENT is optional and can be specified to store remarks or audit information.
DEFERRED option is used to set parameter values for future connecting sessions. Currently active sessions are not affected and they retain the old parameter value. The option is required for parameters that have the ISSSYS_MODIFIABLE column value in V$PARAMETER set to 'DEFERRED'. It is optional if the ISSYS_MODIFIABLE value is set to 'IMMEDIATE'. For static parameters, this cannot be specified.
The SID clause is valid for Real Application Clusters only. Setting this to a specific SID value changes the parameter value for that particular instance only. Setting this to '*' will affect all instances on the cluster--this is the default if the instance was started using the SPFILE. If the instance was started using PFILE then Oracle assumes the current instance as default.
On starting the instance
When an instance is started, if SPFILE is present, it will be used; otherwise, Oracle searches for a default PFILE. If a PFILE is explicitly specified in the STARTUP command Oracle uses it.
SQL> startup pfile=initdb1.ora
In the above case, the PFILE can also have an SPFILE parameter set so that a different SPFILE can be used to start the instance rather than the default one.
There is no option to specify an SPFILE manually while starting the database. This is identified and picked up by Oracle either by using the SPFILE parameter in PFILE or by searching the default paths.
In the next part of this series, we will cover (with examples) the various ways of working with SPFILE and some common issues encountered.
The first part of this series introduced the System Parameter file and its attributes. Below are some practical examples of working with the SPFILE.
Examples of using SPFILE
The examples below were tried on Oracle 10g (10.1.0.2) on Linux platform (FC1). This will behave the same way on other platforms as well.
Creating an SPFILE.
The actual file names can also be specified in the create command.
SQL> create spfile from pfile;
File created.
Creating PFILE from SPFILE.
The actual file names can also be specified in the create command. This option is also known as exporting the SPFILE. This is helpful in the following ways:
1. As a means of text-based backup.
2. For verifying and analyzing the values currently being used.
3. Modifying the export file and then recreating the SPFILE.
SQL> create pfile from spfile;
File created.
SQL> create pfile='initdb1.ora.bkp' from spfile;
File created.
SQL> create pfile='initdb2.ora.bkp' from spfile='spfiledb2.ora';
File created.
Checking at OS level:
[oracle@amzone dbs]$ file initdb1.ora
initdb1.ora: ASCII text
[oracle@amzone dbs]$ file spfiledb1.ora
spfiledb1.ora: data
[oracle@amzone dbs]$ file initdb1.ora.bkp
initdb1.ora.bkp: ASCII text
Providing the wrong file name gives an OS error:-
SQL> create pfile='initdb2.ora.bkp' from spfile='spfiledbx';
create pfile='initdb2.ora.bkp' from spfile='spfiledbx'
*
ERROR at line 1:
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Reverting to PFILE
Reverting to a PFILE can be done by simply creating a PFILE from SPFILE. Remove the existing SPFILE from the default directory. The SPFILE parameter should no longer be present in the PFILE. Oracle resorts to using the PFILE.
Changing static parameters in the SPFILE
There are parameters that cannot be changed in the lifetime of an instance. The database needs to be restarted for the modified parameters to take effect. If SPFILE is enabled, then the only alternative for changing static parameters is to post the changes to the file and not try changing the current instance.
Changing static parameters requires the SPFILE option for the SCOPE parameter with ALTER SYSTEM. These parameters cannot be changed for the presently active instance, i.e., with scope set to MEMORY/BOTH. All parameter that have the column ISSYS_MODIFIABLE column set to FALSE in the V$PARAMETER view, fall in this category. The scope should be SPFILE so that the parameters take effect on the next restart. The example below shows that the ALTER SYSTEM command will not put the new value in the V$PARAMETER view but will show it in the V$SPPARAMETER view as the SPFILE is updated.
SQL> select name, value, issys_modifiable from v$parameter where name = 'utl_file_dir';
NAME VALUE ISSYS_MODIFIABLE
------------------------------ -------------------- ---------------------------
utl_file_dir FALSE
SQL> alter system set utl_file_dir='/tmp' scope=both;
alter system set utl_file_dir='/tmp' scope=both
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
SQL> alter system set utl_file_dir='/tmp' scope=spfile;
System altered.
SQL> select name, value, issys_modifiable from v$parameter where name = 'utl_file_dir';
NAME VALUE ISSYS_MODIFIABLE
------------------------------ -------------------- ---------------------------
utl_file_dir FALSE
SQL> select name, value, isspecified from v$spparameter where name = 'utl_file_dir';
NAME VALUE ISSPECIFIED
------------------------------ -------------------- ------------------
utl_file_dir /tmp TRUE
Using ALTER SYSTEM command
1. Though SPFILE can be created from a PFILE with SYSDBA/SYSOPER privilege (without actually starting the database), parameter values can only be modified with ALTER SYSTEM that will work after the STARTUP command (also in nomount stage) is issued. The example below uses MAX_ENABLED_ROLES parameter; this one is deprecated in Oracle 10g and mentioned here as a sample case only.
SQL> alter system set max_enabled_roles=20 scope=spfile;
alter system set max_enabled_roles=20 scope=spfile
*
ERROR at line 1:
ORA-01034: ORACLE not available
SQL> startup nomount;
ORACLE instance started.
Total System Global Area 146800640 bytes
Fixed Size 777836 bytes
Variable Size 124789140 bytes
Database Buffers 20971520 bytes
Redo Buffers 262144 bytes
SQL> alter system set max_enabled_roles=20 scope=spfile;
System altered.
Identifying the SPFILE being used from V$PARAMETER.
SQL> select name, value from v$parameter where name = 'spfile';
--alternatively, show parameter spfile can also be used.
NAME VALUE
------------ ------------------------------------------------------------
spfile /home/oracle/product/10.1.0/db1/dbs/spfiledb1.ora
SQL> select count(1) from v$spparameter where value is not null;
COUNT(1)
----------
25
SQL> select count(1) from v$spparameter where isspecified = 'TRUE';
COUNT(1)
----------
26
Storing comments for SPFILE changes
Comments can be added along with the parameter value changes in the ALTER SYSTEM command. Only the last provided comment is available. The previous comment is overwritten with the new comment, when provided as part of the command. The UPDATE_COMMENT column in V$SPPARAMETER stores the provided comment.
In case you plan to maintain a log of the changes, one option would be create a routine and change the parameter using it rather than direct statements. This way, the routine can store additional information like the old value, new value provided, comment provided, change date etc., into another table for audit purpose.
SQL> alter system set user_dump_dest = '/home/oracle/product/10.1.0/db1/admin/db1/udump'
2 comment='Changed for maintenance 070804' scope=both;
System altered.
SQL> select name, value from v$parameter where name='user_dump_dest';
NAME VALUE
------------------------------ ----------------------------------------
user_dump_dest /home/oracle/product/10.1.0/db1/admin/db
1/udump
SQL> select name, value, update_comment from v$spparameter where name = 'user_dump_dest';
NAME VALUE UPDATE_COMMENT
----------------- ---------------------------- ------------------------------
user_dump_dest /home/oracle/product/10.1.0/ Changed for maintenance 070804
db1/admin/db1/udump
Working with Control files
Oracle recommends the following method to change the control file path or name.
From SQL*Plus:
SQL> create pfile from spfile;
File created.
SQL> shutdown;
Database closed.
Database dismounted.
ORACLE instance shut down.
OS command prompt:
[oracle@amzone db1]$ vi initdb1.ora
--manually modify the paths of the controlfile or rename them in init.ora.
[oracle@amzone db1]$ cp control01.ctl control01.org
--making a backup copy, just in case.
[oracle@amzone db1]$ mv control01.ctl db1_01.ctl
[oracle@amzone db1]$ mv control02.ctl db1_02.ctl
[oracle@amzone db1]$ mv control03.ctl db1_03.ctl
[oracle@amzone dbs]$ mv spfiledb1.ora spfilexxx.ora
--delete/move the spfile.
Go back to the SQL*Plus session and start the database:
SQL> startup pfile= '/home/oracle/product/10.1.0/db1/dbs/initdb1.ora';
ORACLE instance started.
Total System Global Area 146800640 bytes
Fixed Size 777836 bytes
Variable Size 124789140 bytes
Database Buffers 20971520 bytes
Redo Buffers 262144 bytes
Database mounted.
Database opened.
SQL> create spfile from pfile;
File created.
Shutdown and restart the database to check on the SPFILE usage.
ORA-07446 error
While experimenting on one account I received ORA-07446 for exporting to a PFILE. I could not identify the cause but it was resolved by restarting the SQL*Plus session again.
SQL> startup nomount;
..
SQL> alter system set max_enabled_roles=20 scope=spfile;
System altered.
SQL> alter system set user_dump_dest='/tmp' scope=both;
System altered.
SQL> shutdown immediate;
ORA-01507: database not mounted
ORACLE instance shut down.
SQL> create pfile from spfile;
create pfile from spfile
*
ERROR at line 1:
ORA-07446: sdnfy: bad value '�Q����E' for parameter user_dump_dest.
ORA-07446: sdnfy: bad value '' for parameter user_dump_dest.
Metalink note 166608.1 states that on a first conversion of PFILE to SPFILE, shutting down and trying to start the instance in the same SQL*Plus session gives the 0RA-03113 error. The solution is to simply reconnect as SYSDBA again and start the database.
Bug 2372332 affects version 9.2.0.1 (fixed in 9.2.0.2 and above) and expects the parameters in the SPFILE to be of lower case. Modifying a parameter that is present, in upper case, in the SPFILE, will result in multiple entries in the SPFILE. The alternative is to export the parameters to a PFILE, make changes and re-create an SPFILE from it.
On Fedora Core 1 Platform, the PFILE created from SPFILE looks like the example below. As you can see, the parameters are prefixed with '*.', but these do not cause any issue in starting the database from the PFILE. The SPFILE has a similar format but in binary mode.
*.background_dump_dest='/home/oracle/product/10.1.0/db1/admin/db1/bdump'
*.compatible='10.1.0.2.0'
*.control_files='/home/oracle/product/10.1.0/oradata/db1/control01.ctl',
'/home/oracle/product/10.1.0/oradata/db1/control02.ctl',
'/home/oracle/product/10.1.0/oradata/db1/control03.ctl'
*.core_dump_dest='/home/oracle/product/10.1.0/db1/admin/db1/cdump'
*.db_block_size=8192
*.db_cache_size=20971520
*.db_domain=''
*.db_file_multiblock_read_count=16
*.db_name='db1'
...
Conclusion
As mentioned earlier, the SPFILE option aims at advancing towards oracle's self-tuning capabilities. Just like other database files, SPFILE should also be backed up. It is a good practice to export the SPFILE and store the text format, as a safety measure (as long as it is available!).
(http://www.dbasupport.com/oracle/ora10g/spfile01.shtml)
Some parameters can be dynamically modified to affect the present instance, while others require the instance to be brought down so that changes can take affect. This remains the same when using PFILE or SPFILE. A simple search on the net will reveal a lot of information regarding PFILE and SPFILE.
Parameter files are by default situated in $ORACLE_HOME/dbs (on UNIX) or %ORACLE_HOME%\database (on Windows) directory.
SPFILE
SPFILE stands for Server Parameter File. It is an extension of the initialization parameter storage mechanism, which allows some additional advantages as compared to the simple text based init.ora file. This feature aims at advancing towards Oracle's self-tuning capabilities. As the name states, the file is present on the server side and is not required on the client to start the instance.
*
It is a binary file and the use of editors to modify it is not supported. The only way of changing parameter values is by using the ALTER SYSTEM SET/RESET command.
*
If using the PFILE option, parameter changes done with the ALTER SYSTEM command need to be manually changed in the init.ora file to reflect the changes on future startups. With SPFILE, the ALTER SYSTEM command can update the binary file as well. This allows the changes to be persistent across startups.
*
Since it is binary, it is prone to becoming corrupt if things go wrong. As a backup strategy, create copies of the SPFILE and convert it to a text-based PFILE for safe keeping.
*
The ISSYS_MODIFIABLE column in V$PARAMETER tells us whether the parameters are static or dynamic. Static parameters require the instance to be restarted while dynamic parameters can take effect immediately upon being changed.
SQL> select distinct issys_modifiable from v$parameter;
ISSYS_MODIFIABLE
---------------------------
DEFERRED
FALSE
IMMEDIATE
If the ISSYS_MODIFIABLE value is set to FALSE for a parameter, it means that the parameter cannot change its value in the lifetime of the instance; the database needs to be restarted for changes to take effect. A parameter set to IMMEDATE value means that it is dynamic and can be set to change the present active instance as well as future database restarts. A parameter set to DEFERRED is also dynamic, but changes only affect subsequent sessions, currently active sessions will not be affected and retain the old parameter value.
*
The PFILE is required from the client from where the instance is being started. The SPFILE is not required to be from the client from where the instance is started. This comes in handy when we are trying to start the database remotely.
*
If you have a standby database, the primary database parameter changes are not propagated to the standby. This needs to be done manually and SPFILE does not aid in this.
*
If no SPFILE exists and one needs to be created, Oracle requires that the instance should be started at least once with the PFILE and then the SPFILE created. SPFILE is the default mode in new releases.
*
In a multi-instance Real Application cluster system, a single copy of the SPFILE can be used for all instances. The SPFILE maintains different format styles to support both the common values for all instances as well as specific values for individual instances.
*
The default behavior of the STARTUP command is changed to look for an SPFILE first, when no PFILE option is explicitly specified.
*
The contents of SPFILE can be obtained from V$SPPARAMETER view. The parameters having ISSPECIFIED column set to TRUE are the ones present in the binary file.
*
You only need to be connected as SYSDBA/SYSOPER to create the SPFILE or PFILE. The database need not be started. This option is useful in case the SPFILE has been corrupted and you need to rebuild it from a PFILE.
Which SPFILE on startup
If you have multiple SPFILEs, it will be confusing to identify which file is linked to which instance. By default, the SPFILE name is spfile
1. The alert log can be looked at. If the log shows the SPFILE parameter in "System parameters with non-default value" section, then it is clear that the instance was started with the pfile internally calling the SPFILE using the parameter.
2. Check the SPFILE parameter value in V$PARAMETER view.
ALTER SYSTEM command for SPFILE
SPFILE can be modified by using the ALTER SYSTEM command. This command allows us to set and reset the parameter values.
alter system set
scope=
comment=<'comments'>
deferred
sid=
The SCOPE clause of the command decides how the changes will take effect. This option can have the following values:
MEMORY - changes are active for the current instance only and are lost on restart.
SPFILE - changes are stored in the SPFILE and are activated on the next startup, the presently active instance is not affected. Static parameters need this option to change their values.
BOTH - changes are effective immediately for the present instance and are stored in SPFILE for future startups. This is the default.
COMMENT is optional and can be specified to store remarks or audit information.
DEFERRED option is used to set parameter values for future connecting sessions. Currently active sessions are not affected and they retain the old parameter value. The option is required for parameters that have the ISSSYS_MODIFIABLE column value in V$PARAMETER set to 'DEFERRED'. It is optional if the ISSYS_MODIFIABLE value is set to 'IMMEDIATE'. For static parameters, this cannot be specified.
The SID clause is valid for Real Application Clusters only. Setting this to a specific SID value changes the parameter value for that particular instance only. Setting this to '*' will affect all instances on the cluster--this is the default if the instance was started using the SPFILE. If the instance was started using PFILE then Oracle assumes the current instance as default.
On starting the instance
When an instance is started, if SPFILE is present, it will be used; otherwise, Oracle searches for a default PFILE. If a PFILE is explicitly specified in the STARTUP command Oracle uses it.
SQL> startup pfile=initdb1.ora
In the above case, the PFILE can also have an SPFILE parameter set so that a different SPFILE can be used to start the instance rather than the default one.
There is no option to specify an SPFILE manually while starting the database. This is identified and picked up by Oracle either by using the SPFILE parameter in PFILE or by searching the default paths.
In the next part of this series, we will cover (with examples) the various ways of working with SPFILE and some common issues encountered.
The first part of this series introduced the System Parameter file and its attributes. Below are some practical examples of working with the SPFILE.
Examples of using SPFILE
The examples below were tried on Oracle 10g (10.1.0.2) on Linux platform (FC1). This will behave the same way on other platforms as well.
Creating an SPFILE.
The actual file names can also be specified in the create command.
SQL> create spfile from pfile;
File created.
Creating PFILE from SPFILE.
The actual file names can also be specified in the create command. This option is also known as exporting the SPFILE. This is helpful in the following ways:
1. As a means of text-based backup.
2. For verifying and analyzing the values currently being used.
3. Modifying the export file and then recreating the SPFILE.
SQL> create pfile from spfile;
File created.
SQL> create pfile='initdb1.ora.bkp' from spfile;
File created.
SQL> create pfile='initdb2.ora.bkp' from spfile='spfiledb2.ora';
File created.
Checking at OS level:
[oracle@amzone dbs]$ file initdb1.ora
initdb1.ora: ASCII text
[oracle@amzone dbs]$ file spfiledb1.ora
spfiledb1.ora: data
[oracle@amzone dbs]$ file initdb1.ora.bkp
initdb1.ora.bkp: ASCII text
Providing the wrong file name gives an OS error:-
SQL> create pfile='initdb2.ora.bkp' from spfile='spfiledbx';
create pfile='initdb2.ora.bkp' from spfile='spfiledbx'
*
ERROR at line 1:
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Reverting to PFILE
Reverting to a PFILE can be done by simply creating a PFILE from SPFILE. Remove the existing SPFILE from the default directory. The SPFILE parameter should no longer be present in the PFILE. Oracle resorts to using the PFILE.
Changing static parameters in the SPFILE
There are parameters that cannot be changed in the lifetime of an instance. The database needs to be restarted for the modified parameters to take effect. If SPFILE is enabled, then the only alternative for changing static parameters is to post the changes to the file and not try changing the current instance.
Changing static parameters requires the SPFILE option for the SCOPE parameter with ALTER SYSTEM. These parameters cannot be changed for the presently active instance, i.e., with scope set to MEMORY/BOTH. All parameter that have the column ISSYS_MODIFIABLE column set to FALSE in the V$PARAMETER view, fall in this category. The scope should be SPFILE so that the parameters take effect on the next restart. The example below shows that the ALTER SYSTEM command will not put the new value in the V$PARAMETER view but will show it in the V$SPPARAMETER view as the SPFILE is updated.
SQL> select name, value, issys_modifiable from v$parameter where name = 'utl_file_dir';
NAME VALUE ISSYS_MODIFIABLE
------------------------------ -------------------- ---------------------------
utl_file_dir FALSE
SQL> alter system set utl_file_dir='/tmp' scope=both;
alter system set utl_file_dir='/tmp' scope=both
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
SQL> alter system set utl_file_dir='/tmp' scope=spfile;
System altered.
SQL> select name, value, issys_modifiable from v$parameter where name = 'utl_file_dir';
NAME VALUE ISSYS_MODIFIABLE
------------------------------ -------------------- ---------------------------
utl_file_dir FALSE
SQL> select name, value, isspecified from v$spparameter where name = 'utl_file_dir';
NAME VALUE ISSPECIFIED
------------------------------ -------------------- ------------------
utl_file_dir /tmp TRUE
Using ALTER SYSTEM command
1. Though SPFILE can be created from a PFILE with SYSDBA/SYSOPER privilege (without actually starting the database), parameter values can only be modified with ALTER SYSTEM that will work after the STARTUP command (also in nomount stage) is issued. The example below uses MAX_ENABLED_ROLES parameter; this one is deprecated in Oracle 10g and mentioned here as a sample case only.
SQL> alter system set max_enabled_roles=20 scope=spfile;
alter system set max_enabled_roles=20 scope=spfile
*
ERROR at line 1:
ORA-01034: ORACLE not available
SQL> startup nomount;
ORACLE instance started.
Total System Global Area 146800640 bytes
Fixed Size 777836 bytes
Variable Size 124789140 bytes
Database Buffers 20971520 bytes
Redo Buffers 262144 bytes
SQL> alter system set max_enabled_roles=20 scope=spfile;
System altered.
Identifying the SPFILE being used from V$PARAMETER.
SQL> select name, value from v$parameter where name = 'spfile';
--alternatively, show parameter spfile can also be used.
NAME VALUE
------------ ------------------------------------------------------------
spfile /home/oracle/product/10.1.0/db1/dbs/spfiledb1.ora
SQL> select count(1) from v$spparameter where value is not null;
COUNT(1)
----------
25
SQL> select count(1) from v$spparameter where isspecified = 'TRUE';
COUNT(1)
----------
26
Storing comments for SPFILE changes
Comments can be added along with the parameter value changes in the ALTER SYSTEM command. Only the last provided comment is available. The previous comment is overwritten with the new comment, when provided as part of the command. The UPDATE_COMMENT column in V$SPPARAMETER stores the provided comment.
In case you plan to maintain a log of the changes, one option would be create a routine and change the parameter using it rather than direct statements. This way, the routine can store additional information like the old value, new value provided, comment provided, change date etc., into another table for audit purpose.
SQL> alter system set user_dump_dest = '/home/oracle/product/10.1.0/db1/admin/db1/udump'
2 comment='Changed for maintenance 070804' scope=both;
System altered.
SQL> select name, value from v$parameter where name='user_dump_dest';
NAME VALUE
------------------------------ ----------------------------------------
user_dump_dest /home/oracle/product/10.1.0/db1/admin/db
1/udump
SQL> select name, value, update_comment from v$spparameter where name = 'user_dump_dest';
NAME VALUE UPDATE_COMMENT
----------------- ---------------------------- ------------------------------
user_dump_dest /home/oracle/product/10.1.0/ Changed for maintenance 070804
db1/admin/db1/udump
Working with Control files
Oracle recommends the following method to change the control file path or name.
From SQL*Plus:
SQL> create pfile from spfile;
File created.
SQL> shutdown;
Database closed.
Database dismounted.
ORACLE instance shut down.
OS command prompt:
[oracle@amzone db1]$ vi initdb1.ora
--manually modify the paths of the controlfile or rename them in init.ora.
[oracle@amzone db1]$ cp control01.ctl control01.org
--making a backup copy, just in case.
[oracle@amzone db1]$ mv control01.ctl db1_01.ctl
[oracle@amzone db1]$ mv control02.ctl db1_02.ctl
[oracle@amzone db1]$ mv control03.ctl db1_03.ctl
[oracle@amzone dbs]$ mv spfiledb1.ora spfilexxx.ora
--delete/move the spfile.
Go back to the SQL*Plus session and start the database:
SQL> startup pfile= '/home/oracle/product/10.1.0/db1/dbs/initdb1.ora';
ORACLE instance started.
Total System Global Area 146800640 bytes
Fixed Size 777836 bytes
Variable Size 124789140 bytes
Database Buffers 20971520 bytes
Redo Buffers 262144 bytes
Database mounted.
Database opened.
SQL> create spfile from pfile;
File created.
Shutdown and restart the database to check on the SPFILE usage.
ORA-07446 error
While experimenting on one account I received ORA-07446 for exporting to a PFILE. I could not identify the cause but it was resolved by restarting the SQL*Plus session again.
SQL> startup nomount;
..
SQL> alter system set max_enabled_roles=20 scope=spfile;
System altered.
SQL> alter system set user_dump_dest='/tmp' scope=both;
System altered.
SQL> shutdown immediate;
ORA-01507: database not mounted
ORACLE instance shut down.
SQL> create pfile from spfile;
create pfile from spfile
*
ERROR at line 1:
ORA-07446: sdnfy: bad value '�Q����E' for parameter user_dump_dest.
ORA-07446: sdnfy: bad value '' for parameter user_dump_dest.
Metalink note 166608.1 states that on a first conversion of PFILE to SPFILE, shutting down and trying to start the instance in the same SQL*Plus session gives the 0RA-03113 error. The solution is to simply reconnect as SYSDBA again and start the database.
Bug 2372332 affects version 9.2.0.1 (fixed in 9.2.0.2 and above) and expects the parameters in the SPFILE to be of lower case. Modifying a parameter that is present, in upper case, in the SPFILE, will result in multiple entries in the SPFILE. The alternative is to export the parameters to a PFILE, make changes and re-create an SPFILE from it.
On Fedora Core 1 Platform, the PFILE created from SPFILE looks like the example below. As you can see, the parameters are prefixed with '*.', but these do not cause any issue in starting the database from the PFILE. The SPFILE has a similar format but in binary mode.
*.background_dump_dest='/home/oracle/product/10.1.0/db1/admin/db1/bdump'
*.compatible='10.1.0.2.0'
*.control_files='/home/oracle/product/10.1.0/oradata/db1/control01.ctl',
'/home/oracle/product/10.1.0/oradata/db1/control02.ctl',
'/home/oracle/product/10.1.0/oradata/db1/control03.ctl'
*.core_dump_dest='/home/oracle/product/10.1.0/db1/admin/db1/cdump'
*.db_block_size=8192
*.db_cache_size=20971520
*.db_domain=''
*.db_file_multiblock_read_count=16
*.db_name='db1'
...
Conclusion
As mentioned earlier, the SPFILE option aims at advancing towards oracle's self-tuning capabilities. Just like other database files, SPFILE should also be backed up. It is a good practice to export the SPFILE and store the text format, as a safety measure (as long as it is available!).
(http://www.dbasupport.com/oracle/ora10g/spfile01.shtml)
Tuesday, April 04, 2006
Untapped PC market opportunities lie in Pakistan, Sri Lanka, and Bangladesh, says IDC
IDC's quarterly PC tracker on emerging Asian markets shows that the client PC market in Pakistan, Bangladesh and Sri Lanka totaled 393,184 units in the second half of 2005, thus bringing full year 2005 shipments to 851,735 units, representing a 16% growth for the year.
With full year growth of 19%, Pakistan boasted the highest growth rate among the three markets, while Bangladesh and Sri Lanka achieved respectable 13% and 12% growth rates respectively.
"Despite some dampeners in 2005, such as risky peace talks and the after-effects of the tsunami, the PC market in Sri Lanka exhibited resiliency largely due to public sector and non-government organization purchases," said Andrew Wong, Research Manager of Emerging Asia Countries Personal Systems Research at IDC. "In Pakistan, encouraging government-led policies and structural liberalization in the financial and telecommunications sectors helped to lift the PC market there. Bangladesh, on the other hand, was relatively unaffected by the influx of second-hand PCs, thus allowing the market to move ahead."
Future Outlook
The challenges in these countries are numerous, yet they present many opportunities for current vendors and potential new entrants. Over the long term, IDC predicts that the compounded annual growth rate from 2006-2010 for Pakistan, Bangladesh and Sri Lanka will reach 19%, 22% and 11% respectively, largely driven by public sector purchases, as well as the telecommunications and financial services sectors.
"The compounded annual growth rates expected in these three countries make the rest of the APEJ market look dull in comparison," says Bryan Ma, Associate Director of Asia/Pacific Personal Systems Research at IDC. "In fact, Pakistan's total market size could exceed the much more developed Singapore PC market in absolute terms as early as 2007."
Still, vendors will face wild cards from the political, social and economic angles. Faced with a delicate balancing act in ensuring sustainable business models, vendors should strengthen partnerships with the local vendors or channels, especially when pursuing the government, education and financial sectors. For instance, multinational vendors in Sri Lanka can partner with a local system integrator or value added-reseller to reduce costs and to get access to government contracts. This approach can be especially useful for vendors who wish to venture into this market in the midst of a rapidly changing environment.
Competitive Analysis
In Pakistan, local branded PC vendors such as In-Box and Raffles achieved commendable market share in the past year by banking on government and education projects. But multinational PC vendor HP grew 38.5% year-on-year to take the top spot in Sri Lanka in 2005 thanks to projects in the government, corporate, and education sectors. Similarly, HP overtook local incumbent Daffodil for the top spot in Bangladesh in 2005, where the government, education, finance, and agriculture sectors generated multiple small-scale projects throughout the year.
Pakistan, Sri Lanka and Bangladesh Client PC Shipments by Top 3 Vendors, 2004 and 2005


Source: IDC, March 2006
Sri Lanka, Pakistan and Bangladesh Client PC Unit Shipment Forecast, 2005-2010

Source: IDC, March 2006
For more information about purchasing the research, please contact Selina Ang at +65-6228-7717 or sang@idc.com. For press enquiries, please contact Holly Fung at +852-2905-4225 or hfung@idc.com.
(http://www.emsnow.com/npps/print.cfm)
With full year growth of 19%, Pakistan boasted the highest growth rate among the three markets, while Bangladesh and Sri Lanka achieved respectable 13% and 12% growth rates respectively.
"Despite some dampeners in 2005, such as risky peace talks and the after-effects of the tsunami, the PC market in Sri Lanka exhibited resiliency largely due to public sector and non-government organization purchases," said Andrew Wong, Research Manager of Emerging Asia Countries Personal Systems Research at IDC. "In Pakistan, encouraging government-led policies and structural liberalization in the financial and telecommunications sectors helped to lift the PC market there. Bangladesh, on the other hand, was relatively unaffected by the influx of second-hand PCs, thus allowing the market to move ahead."
Future Outlook
The challenges in these countries are numerous, yet they present many opportunities for current vendors and potential new entrants. Over the long term, IDC predicts that the compounded annual growth rate from 2006-2010 for Pakistan, Bangladesh and Sri Lanka will reach 19%, 22% and 11% respectively, largely driven by public sector purchases, as well as the telecommunications and financial services sectors.
"The compounded annual growth rates expected in these three countries make the rest of the APEJ market look dull in comparison," says Bryan Ma, Associate Director of Asia/Pacific Personal Systems Research at IDC. "In fact, Pakistan's total market size could exceed the much more developed Singapore PC market in absolute terms as early as 2007."
Still, vendors will face wild cards from the political, social and economic angles. Faced with a delicate balancing act in ensuring sustainable business models, vendors should strengthen partnerships with the local vendors or channels, especially when pursuing the government, education and financial sectors. For instance, multinational vendors in Sri Lanka can partner with a local system integrator or value added-reseller to reduce costs and to get access to government contracts. This approach can be especially useful for vendors who wish to venture into this market in the midst of a rapidly changing environment.
Competitive Analysis
In Pakistan, local branded PC vendors such as In-Box and Raffles achieved commendable market share in the past year by banking on government and education projects. But multinational PC vendor HP grew 38.5% year-on-year to take the top spot in Sri Lanka in 2005 thanks to projects in the government, corporate, and education sectors. Similarly, HP overtook local incumbent Daffodil for the top spot in Bangladesh in 2005, where the government, education, finance, and agriculture sectors generated multiple small-scale projects throughout the year.
Pakistan, Sri Lanka and Bangladesh Client PC Shipments by Top 3 Vendors, 2004 and 2005
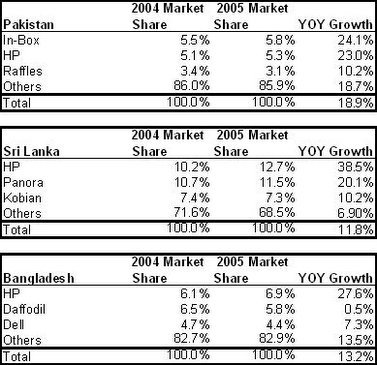
Source: IDC, March 2006
Sri Lanka, Pakistan and Bangladesh Client PC Unit Shipment Forecast, 2005-2010
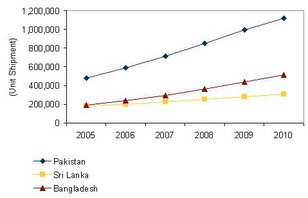
Source: IDC, March 2006
For more information about purchasing the research, please contact Selina Ang at +65-6228-7717 or sang@idc.com. For press enquiries, please contact Holly Fung at +852-2905-4225 or hfung@idc.com.
(http://www.emsnow.com/npps/print.cfm)
Enterprise Portals at Non-Enterprise Prices (free, that is)
The Enterprise Information Portal (EIP) has certainly become one of the major enterprise software categories of the day. While the definition varies somewhat from vendor to vendor, a portal is basically a dynamic Web site containing multiple modules (often called portlets or gadgets or other goofy names), the display of which can be customized by each user. Portals contain a user security methodology, ideally including a single sign-on so users can log in to all of the modules at once.
If you need a real-world example, think of the application behind My Yahoo!. The difference would be that in most enterprise environments, corporations set up portals to enable their partners, customers or vendors to log in and view critical information about their company. This can include information from corporate databases and other back office software, e- commerce applications, other Web-enabled applications and an unlimited amount of data from content management systems, syndication sources and more.
Numerous software vendors have portal solutions available. At the high end, Plumtree, IBM, SAP, BEA and other similar solutions have unbelievably high license fees. Add in the costs of integration and implementing and EIP solution can easily run up in the million dollar figures. Other companies, including Microsoft and Sybase offer solutions with a lower license fee. The reality is that many companies don't need everything these solutions offer. Most, if not all, high-end solutions have application integration features that allow for (relatively) simple integration with ERP and other back office solutions, truly a key factor for Fortune 1000 companies, as well as built-in application servers and content management solutions. For many small-to-medium enterprise companies, this is way more than is needed or even desired.
This is where the solutions reviewed below really shine (in varying degrees). Most of these solutions offer a skeletal form of what would be expected in an EIP solution, but are quite sufficient for a J2EE developer to begin their portal development process and save a significant amount of coding time working with underlying processes, such as authentication and personalization.
Enterprise Portals Key Review Factors
There are quite a few open source and free EIP solutions available, but many fewer in the J2EE world, though in many ways J2EE is a natural fit for portals. In addition to the helpful API's for data integration (such as Java DataBase Connectivity [JDBC], Java Connector Architecture [JCA] and Java Naming Directory Interface [JNDI]), tremendous strides are being made to make it even better: a portlet API is currently under review (see JSR-168 specs) and Java's Web Services implementation are both great examples of this.
Though what every company is looking for in a portal solution is variable, I reviewed these based on the following items:
Installation and setup: How easy was it to install? What J2EE application servers are supported?
Documentation: Was there documentation? Of what quality?
"Out of the (proverbial) box" features: What features come with the portal without requiring additional programming? How good are the implementations? Anything expected that isn't there?
Ease of customization: If changes are required, how difficult is it to get into the code and make them?
Additional bonus features: Does the portal have any features beyond authentication and site customization?
Portlet API: How difficult is it to create or modify applications to be used as modules? What types of portlets can be used?
These 4 portal solutions seemed the best for review purposes:
Apache Jetspeed
jPorta
Liferay
RedHat CCM (formerly ArsDigita)
Apache Jetspeed

If you have done any research into J2EE portal application, Jetspeed is sure to turn up. A part of the Apache Jakarta project (Apache's J2EE segment), Jetspeed has been around since 1999 and members of the Jetspeed project are active participants in the JSR-168 portlet API specifications (other participants include IBM, BEA Systems, Borland and Epicentric). All of these factors make Jetspeed one of the better options.
Jetspeed uses XML extensively for display and back-end functionality. This includes simple use of RSS feeds and XML data into portlets and WAP cell phone site delivery. Additionally, Portal Structure Markup Language (PSML) is used to store portal-specific information including styles, personalization information and portlet registries.
The documentation is fairly good overall - improved significantly with a tutorial for the 1.4b3 release. Additionally, FAQ's, sample sites, Javadocs and other information is readily available via the Jetspeed home page.
Beyond basic user storage and preference settings and portlet integration, Jetspeed offers a number of nice features. The administrative interface is intuitive. Content can be syndicated and syndicated content can be accessed as portlets. It will be standardized on the portlet specification, enabling absorption of third-party portlet applications. Currently, numerous types of applications can be integrated as portlets including: RSS, JSP, servlets, external Web page, XSL, Velocity, a database browser and more. Data can be integrated with Avantgo. It is also highly portable between J2EE servers using the JDK 1.2 and Servlet 2.2 specifications.
The only weakness I could find with Jetspeed was that its not very customizable. Customizing Jetspeed requires not only knowledge of J2EE programming concepts, but also the Turbine application framework. This isn't inherently a weakness. Building applications on top of existing frameworks is laudable and is a good development strategy. However, not knowing Turbine will add to the learning curve of understanding how Jetspeed works. Note also, that some templates are written using the Velocity template engine (Turbine has Velocity built in).
Mentum Group jPorta
Where Jetspeed is a full-feature strategy, jPorta is a much more scaled-down solution. Which can be beneficial, depending on the need. The documentation is well-designed, and describes the basic functioning, including how to use the XML-based gadget (portlet) registry, the layout manager and gadget tag usage syntax (jPorta uses JSP custom tags for much of its functioning). Installation instructions are only provided for JBoss/Tomcat, although the documents say it will work with any servlet 2.3 engine. I was able to easily deploy the application WAR file on JRun4, but wasn't able to log in for unknown reasons.
This last topic leads to Jeenius, the framework underlying jPorta that handles a number of lower-end management functions, much like the JavaServer Tags do. The most notable and deepest use of Jeenius is to handle all of the security (e.g. users and roles) and user profile information. Anyone interested in customizing jPorta will inevitably need to at least understand what Jeenius handles. For example, to troubleshoot my login issue, I will need to see what is happening with Jeenius' tag.
The good news is that both jPorta and Jeenius are fairly easy to learn. Both use JSP extensively to handle all of the display, relying on underlying custom tags to do the core of the work. This means that customization is remarkably easy, even for less-experienced J2EE developers. The code is very clean and the tag API is intuitive. If you are looking for a simple solution to display some simple servlet, HTML or JSP-based application as gadgets, jPorta would be quite viable. A number of sample gadgets are included that provide a good example for how to develop portlet-type applications for jPorta.
Liferay

Liferay was developed out of the lack of a lower end portal solution. Of all the portals reviewed, Liferay has the best Web site and accompanying documentation. Check out the FAQ). The result is a pretty deep solution that handles not just the basic users and portlet drawing, but also has a full administrative interface, documented support for all of the major databases, documented support for the main J2EE application servers (JBoss/Jetty, JBoss/TomCat, Oracle AS, Pramati, WebLogic, Orion, and more coming soon, see site for versions and latest details) and single sign-on capabilities. Did I mention it also supports multiple languages?
Liferay is a true J2EE application, relying on numerous patterns, EJBs and built on top of the Struts platform. Many J2EE developers are familiar with Struts, making this a good call for an underlying framework. An XML-based registry is also used to store portlets. A number of portlets are included, including a guestbook, a calendar, a mapping utility using Expedia, news, polls, a document library, live stock information and more (including Bible verses). It's a great start for anyone launching a portal project. I was unable to determine what the API is for developing portlets, it looks like EJBs are used for this. In addition to the included portlets, Apache Lucene is used to enable document searching. XML is supported and it looks like Web services.
Liferay is clearly a good option, especially for anyone who is familiar with Struts. Of course because Liferay is a complete application, it will work well for many companies out of the box. The only concern I would have would be how easy or difficult it is to develop portlets.
RedHat CCM

Everyone is familiar with RedHat of Linux fame. RedHat has now incorporated the ArsDigita content management solution into their book of offerings, now called the RedHat Content and Collaboration Management (CCM) Software Solutions. CCM is obviously a content management solution at heart, but because it offers many portal-like features, and because many portal projects focus on delivering content only, this is certainly a product worth taking a look at.
The documentation, and this is one of the advantages of RedHat software, is good and detailed. In addition, RedHat offers support and consulting if you should get stuck using their products. The installation documentation covers TomCat 3 & 4, Resin and WebSphere. All instructions assume you are using Linux, or at least Unix. Which is not to say it won't run on Windows, you're just on your own. No support available to get you up and running.
Customization of CCM is possible. The development docs are fairly extensive. Again, this is primarily a content management tool, and though I could find portlet-type classes in the Javadocs, there wasn't anything specifically about developing portlets in the documentation. That said, ArsDigita was around for a while and the application itself is quite large at this point in time. A significant Java library powers CCM. XML/XSTL are used on the front-end, which is always a plus, especially for content management.
The feature list is quite extensive and includes user/group management, work flows and support for multiple languages. Of course the content repository is the core aspect of this package and something not included, to this extent, in any of the other solutions. The XSLT front-end will also allow for VoiceXML, WML or other XML displays. If you need a portal solution with less on the back-end and an integrated content management solution then this package is worth evaluating. Keep in mind that only the evaluation version is free.
Conclusion
I would recommend any of these portal solutions. Which one you choose will depend primarily on what you specifically need. jPorta offers a simple solution that is easy for JSP developers to implement. Both Jetspeed and Liferay offer fairly robust J2EE solutions that will offer a full portal framework. Liferay contains a great feature set and good documentation. Jetspeed also has a fairly good feature set and will support JSR-168. Finally, the RedHat solution is a good one for any company who wants the look-and-feel of a portal and a content manager to back it up.
(http://javaboutique.internet.com/reviews/Enterprise_Portals/index-5.html)
If you need a real-world example, think of the application behind My Yahoo!. The difference would be that in most enterprise environments, corporations set up portals to enable their partners, customers or vendors to log in and view critical information about their company. This can include information from corporate databases and other back office software, e- commerce applications, other Web-enabled applications and an unlimited amount of data from content management systems, syndication sources and more.
Numerous software vendors have portal solutions available. At the high end, Plumtree, IBM, SAP, BEA and other similar solutions have unbelievably high license fees. Add in the costs of integration and implementing and EIP solution can easily run up in the million dollar figures. Other companies, including Microsoft and Sybase offer solutions with a lower license fee. The reality is that many companies don't need everything these solutions offer. Most, if not all, high-end solutions have application integration features that allow for (relatively) simple integration with ERP and other back office solutions, truly a key factor for Fortune 1000 companies, as well as built-in application servers and content management solutions. For many small-to-medium enterprise companies, this is way more than is needed or even desired.
This is where the solutions reviewed below really shine (in varying degrees). Most of these solutions offer a skeletal form of what would be expected in an EIP solution, but are quite sufficient for a J2EE developer to begin their portal development process and save a significant amount of coding time working with underlying processes, such as authentication and personalization.
Enterprise Portals Key Review Factors
There are quite a few open source and free EIP solutions available, but many fewer in the J2EE world, though in many ways J2EE is a natural fit for portals. In addition to the helpful API's for data integration (such as Java DataBase Connectivity [JDBC], Java Connector Architecture [JCA] and Java Naming Directory Interface [JNDI]), tremendous strides are being made to make it even better: a portlet API is currently under review (see JSR-168 specs) and Java's Web Services implementation are both great examples of this.
Though what every company is looking for in a portal solution is variable, I reviewed these based on the following items:
Installation and setup: How easy was it to install? What J2EE application servers are supported?
Documentation: Was there documentation? Of what quality?
"Out of the (proverbial) box" features: What features come with the portal without requiring additional programming? How good are the implementations? Anything expected that isn't there?
Ease of customization: If changes are required, how difficult is it to get into the code and make them?
Additional bonus features: Does the portal have any features beyond authentication and site customization?
Portlet API: How difficult is it to create or modify applications to be used as modules? What types of portlets can be used?
These 4 portal solutions seemed the best for review purposes:
Apache Jetspeed
jPorta
Liferay
RedHat CCM (formerly ArsDigita)
Apache Jetspeed

If you have done any research into J2EE portal application, Jetspeed is sure to turn up. A part of the Apache Jakarta project (Apache's J2EE segment), Jetspeed has been around since 1999 and members of the Jetspeed project are active participants in the JSR-168 portlet API specifications (other participants include IBM, BEA Systems, Borland and Epicentric). All of these factors make Jetspeed one of the better options.
Jetspeed uses XML extensively for display and back-end functionality. This includes simple use of RSS feeds and XML data into portlets and WAP cell phone site delivery. Additionally, Portal Structure Markup Language (PSML) is used to store portal-specific information including styles, personalization information and portlet registries.
The documentation is fairly good overall - improved significantly with a tutorial for the 1.4b3 release. Additionally, FAQ's, sample sites, Javadocs and other information is readily available via the Jetspeed home page.
Beyond basic user storage and preference settings and portlet integration, Jetspeed offers a number of nice features. The administrative interface is intuitive. Content can be syndicated and syndicated content can be accessed as portlets. It will be standardized on the portlet specification, enabling absorption of third-party portlet applications. Currently, numerous types of applications can be integrated as portlets including: RSS, JSP, servlets, external Web page, XSL, Velocity, a database browser and more. Data can be integrated with Avantgo. It is also highly portable between J2EE servers using the JDK 1.2 and Servlet 2.2 specifications.
The only weakness I could find with Jetspeed was that its not very customizable. Customizing Jetspeed requires not only knowledge of J2EE programming concepts, but also the Turbine application framework. This isn't inherently a weakness. Building applications on top of existing frameworks is laudable and is a good development strategy. However, not knowing Turbine will add to the learning curve of understanding how Jetspeed works. Note also, that some templates are written using the Velocity template engine (Turbine has Velocity built in).
Mentum Group jPorta
Where Jetspeed is a full-feature strategy, jPorta is a much more scaled-down solution. Which can be beneficial, depending on the need. The documentation is well-designed, and describes the basic functioning, including how to use the XML-based gadget (portlet) registry, the layout manager and gadget tag usage syntax (jPorta uses JSP custom tags for much of its functioning). Installation instructions are only provided for JBoss/Tomcat, although the documents say it will work with any servlet 2.3 engine. I was able to easily deploy the application WAR file on JRun4, but wasn't able to log in for unknown reasons.
This last topic leads to Jeenius, the framework underlying jPorta that handles a number of lower-end management functions, much like the JavaServer Tags do. The most notable and deepest use of Jeenius is to handle all of the security (e.g. users and roles) and user profile information. Anyone interested in customizing jPorta will inevitably need to at least understand what Jeenius handles. For example, to troubleshoot my login issue, I will need to see what is happening with Jeenius'
The good news is that both jPorta and Jeenius are fairly easy to learn. Both use JSP extensively to handle all of the display, relying on underlying custom tags to do the core of the work. This means that customization is remarkably easy, even for less-experienced J2EE developers. The code is very clean and the tag API is intuitive. If you are looking for a simple solution to display some simple servlet, HTML or JSP-based application as gadgets, jPorta would be quite viable. A number of sample gadgets are included that provide a good example for how to develop portlet-type applications for jPorta.
Liferay
Liferay was developed out of the lack of a lower end portal solution. Of all the portals reviewed, Liferay has the best Web site and accompanying documentation. Check out the FAQ). The result is a pretty deep solution that handles not just the basic users and portlet drawing, but also has a full administrative interface, documented support for all of the major databases, documented support for the main J2EE application servers (JBoss/Jetty, JBoss/TomCat, Oracle AS, Pramati, WebLogic, Orion, and more coming soon, see site for versions and latest details) and single sign-on capabilities. Did I mention it also supports multiple languages?
Liferay is a true J2EE application, relying on numerous patterns, EJBs and built on top of the Struts platform. Many J2EE developers are familiar with Struts, making this a good call for an underlying framework. An XML-based registry is also used to store portlets. A number of portlets are included, including a guestbook, a calendar, a mapping utility using Expedia, news, polls, a document library, live stock information and more (including Bible verses). It's a great start for anyone launching a portal project. I was unable to determine what the API is for developing portlets, it looks like EJBs are used for this. In addition to the included portlets, Apache Lucene is used to enable document searching. XML is supported and it looks like Web services.
Liferay is clearly a good option, especially for anyone who is familiar with Struts. Of course because Liferay is a complete application, it will work well for many companies out of the box. The only concern I would have would be how easy or difficult it is to develop portlets.
RedHat CCM
Everyone is familiar with RedHat of Linux fame. RedHat has now incorporated the ArsDigita content management solution into their book of offerings, now called the RedHat Content and Collaboration Management (CCM) Software Solutions. CCM is obviously a content management solution at heart, but because it offers many portal-like features, and because many portal projects focus on delivering content only, this is certainly a product worth taking a look at.
The documentation, and this is one of the advantages of RedHat software, is good and detailed. In addition, RedHat offers support and consulting if you should get stuck using their products. The installation documentation covers TomCat 3 & 4, Resin and WebSphere. All instructions assume you are using Linux, or at least Unix. Which is not to say it won't run on Windows, you're just on your own. No support available to get you up and running.
Customization of CCM is possible. The development docs are fairly extensive. Again, this is primarily a content management tool, and though I could find portlet-type classes in the Javadocs, there wasn't anything specifically about developing portlets in the documentation. That said, ArsDigita was around for a while and the application itself is quite large at this point in time. A significant Java library powers CCM. XML/XSTL are used on the front-end, which is always a plus, especially for content management.
The feature list is quite extensive and includes user/group management, work flows and support for multiple languages. Of course the content repository is the core aspect of this package and something not included, to this extent, in any of the other solutions. The XSLT front-end will also allow for VoiceXML, WML or other XML displays. If you need a portal solution with less on the back-end and an integrated content management solution then this package is worth evaluating. Keep in mind that only the evaluation version is free.
Conclusion
I would recommend any of these portal solutions. Which one you choose will depend primarily on what you specifically need. jPorta offers a simple solution that is easy for JSP developers to implement. Both Jetspeed and Liferay offer fairly robust J2EE solutions that will offer a full portal framework. Liferay contains a great feature set and good documentation. Jetspeed also has a fairly good feature set and will support JSR-168. Finally, the RedHat solution is a good one for any company who wants the look-and-feel of a portal and a content manager to back it up.
(http://javaboutique.internet.com/reviews/Enterprise_Portals/index-5.html)
The Role of Standards in Enterprise Content Management by Colin White
My recent article, Consolidating, Accessing and Analyzing Unstructured Data, highlighted the growing importance of unstructured data in data integration projects. It also discussed the industry direction toward the use of enterprise content management (ECM) systems for managing the increasing volume of unstructured and semi-structured data in organizations. In this month’s newsletter, I want to continue the discussion of ECM by looking at how industry standards in this area are likely to ease the integration of unstructured and semi-structured data into the business environment.
Most ECM systems consist of a set of content services, which I will call the ECM application, and a content repository. The ECM application provides the tools for interacting with business content, whereas the repository handles the management of the content. Although the repository typically employs an underlying database or file system for storing the content, the data interface to the repository and the data model employed by the repository are usually proprietary. In many cases, the repository is tightly coupled with the ECM application, and its data interface is not always available for use by external applications. This means that third-party products can only access the repository content at the application level, assuming of course that the ECM product provides a documented application program interface (API). Even if a repository-level data interface is available, third-party products and IT applications must create unique interface adapters for each ECM product.
The proprietary nature of ECM applications and their content repositories is similar to the situation with packaged business transaction applications. These latter applications employ standard relational database systems, but direct access to the data is not usually possible; and, as with ECM systems, often the only way to access the data is at the application level.
The trend of both ECM and packaged application vendors is to provide Web services interfaces to their products. Although this approach simplifies and standardizes access to ECM and packaged business transaction applications, access is still done at the application level, rather than at the data level.
Web services access to an ECM system at the application level works okay if the ECM application is to be incorporated into a workflow or composite application, for example, as a part of service-oriented architecture (SOA). If, however, an external application needs to access a content repository at the data interface level, another approach is required. The solution is to separate ECM applications from their content repositories and to provide a standardized interface for accessing repository content. Such an architecture is provided by Content Repository API for Java Technology (known as JCR).
The Java Content Repository
JCR is “an ongoing effort to define a standard repository interface for the J2SE/J2EE platforms. The goal of a content repository API is to abstract the details of application data storage and retrieval such that many different applications can use the same interface, for multiple purposes, without significant performance degradation. Content services can then be layered on top of that abstraction to enable software reuse and reduce application development time.” (Source: Roy Fielding. JSR 170 Overview: Standardizing the Content Repository Interface. Day Software White Paper, March 2005.)
Industry standards for the Java are developed using the Java Community Process (JCP). Members of the JCP participate in the development of specifications, referred to as Java Specification Requests (JSRs). The specification for the Java Content Repository is known as JSR 170, which recently became a formal standard. The standard was proposed by Day Software and involved experts from leading organizations such as BEA, EMC (Documentum), FileNet, Fujitsu, Hummingbird, IBM, Vignette and the Apache Software Foundation. A second version of the JCR is now in development and is known as JSR 283.
JSR 170 supports three implementation levels. Level 1 provides a read-only repository and supports content export via XML. The export capability allows the content to be moved to other platforms, including a Level 2 repository. Level 2 adds a write capability and content import via XML. Level 3 adds versioning. It is important to emphasize that JSR 170 is an API and not a protocol; therefore, protocols such as HTTP and WebDAV can be used in conjunction with JSR 170.
Most ECM vendors are expected to focus on providing Level 1 support, which will allow the contents in their proprietary repositories to be accessed in read-only mode. It is interesting to note, however, that Day Software is marketing a Level 3 repository known as Content Repository Extreme (CRX). The company is also developing repository connectors for other ECM products. The first of these to be delivered is for EMC Documentum. The connector will make content stored in the Documentum repository accessible using the JSR 170 interface. Other Day connectors that are in development include interfaces for FileNet, IBM Domino.doc, Interwoven, Microsoft SharePoint, Open Text LiveLink, and Software AG Tamino. The connectors support content reading and writing, and both SQL and XPath querying and searching.
An open source reference platform (known as Jackrabbit) developed by Day Software for JSR 170 can be obtained from the Apache Software Foundation. This reference platform is currently an incubator project, but is expected to move to a full Apache project in the near future.
Moving to an Enterprise Approach
Many organizations are moving toward an enterprise approach to data integration. Today, this integration is focused on structured data, but there is increasing interest in adding support for integrating unstructured and semi-structured data to enterprise projects. Many integration technologies (EII, ETL and business portals, for example) are beginning to support this latter type of business content, but it is expensive to develop and support custom adapters for each type of content repository. Web services provide a certain level of integration, but for full data integration it will be important to separate ECM applications from their underlying repositories and support a universal repository interface. The JCR standard is the first step in supporting this process.
(http://www.b-eye-network.com/view/257)
Most ECM systems consist of a set of content services, which I will call the ECM application, and a content repository. The ECM application provides the tools for interacting with business content, whereas the repository handles the management of the content. Although the repository typically employs an underlying database or file system for storing the content, the data interface to the repository and the data model employed by the repository are usually proprietary. In many cases, the repository is tightly coupled with the ECM application, and its data interface is not always available for use by external applications. This means that third-party products can only access the repository content at the application level, assuming of course that the ECM product provides a documented application program interface (API). Even if a repository-level data interface is available, third-party products and IT applications must create unique interface adapters for each ECM product.
The proprietary nature of ECM applications and their content repositories is similar to the situation with packaged business transaction applications. These latter applications employ standard relational database systems, but direct access to the data is not usually possible; and, as with ECM systems, often the only way to access the data is at the application level.
The trend of both ECM and packaged application vendors is to provide Web services interfaces to their products. Although this approach simplifies and standardizes access to ECM and packaged business transaction applications, access is still done at the application level, rather than at the data level.
Web services access to an ECM system at the application level works okay if the ECM application is to be incorporated into a workflow or composite application, for example, as a part of service-oriented architecture (SOA). If, however, an external application needs to access a content repository at the data interface level, another approach is required. The solution is to separate ECM applications from their content repositories and to provide a standardized interface for accessing repository content. Such an architecture is provided by Content Repository API for Java Technology (known as JCR).
The Java Content Repository
JCR is “an ongoing effort to define a standard repository interface for the J2SE/J2EE platforms. The goal of a content repository API is to abstract the details of application data storage and retrieval such that many different applications can use the same interface, for multiple purposes, without significant performance degradation. Content services can then be layered on top of that abstraction to enable software reuse and reduce application development time.” (Source: Roy Fielding. JSR 170 Overview: Standardizing the Content Repository Interface. Day Software White Paper, March 2005.)
Industry standards for the Java are developed using the Java Community Process (JCP). Members of the JCP participate in the development of specifications, referred to as Java Specification Requests (JSRs). The specification for the Java Content Repository is known as JSR 170, which recently became a formal standard. The standard was proposed by Day Software and involved experts from leading organizations such as BEA, EMC (Documentum), FileNet, Fujitsu, Hummingbird, IBM, Vignette and the Apache Software Foundation. A second version of the JCR is now in development and is known as JSR 283.
JSR 170 supports three implementation levels. Level 1 provides a read-only repository and supports content export via XML. The export capability allows the content to be moved to other platforms, including a Level 2 repository. Level 2 adds a write capability and content import via XML. Level 3 adds versioning. It is important to emphasize that JSR 170 is an API and not a protocol; therefore, protocols such as HTTP and WebDAV can be used in conjunction with JSR 170.
Most ECM vendors are expected to focus on providing Level 1 support, which will allow the contents in their proprietary repositories to be accessed in read-only mode. It is interesting to note, however, that Day Software is marketing a Level 3 repository known as Content Repository Extreme (CRX). The company is also developing repository connectors for other ECM products. The first of these to be delivered is for EMC Documentum. The connector will make content stored in the Documentum repository accessible using the JSR 170 interface. Other Day connectors that are in development include interfaces for FileNet, IBM Domino.doc, Interwoven, Microsoft SharePoint, Open Text LiveLink, and Software AG Tamino. The connectors support content reading and writing, and both SQL and XPath querying and searching.
An open source reference platform (known as Jackrabbit) developed by Day Software for JSR 170 can be obtained from the Apache Software Foundation. This reference platform is currently an incubator project, but is expected to move to a full Apache project in the near future.
Moving to an Enterprise Approach
Many organizations are moving toward an enterprise approach to data integration. Today, this integration is focused on structured data, but there is increasing interest in adding support for integrating unstructured and semi-structured data to enterprise projects. Many integration technologies (EII, ETL and business portals, for example) are beginning to support this latter type of business content, but it is expensive to develop and support custom adapters for each type of content repository. Web services provide a certain level of integration, but for full data integration it will be important to separate ECM applications from their underlying repositories and support a universal repository interface. The JCR standard is the first step in supporting this process.
(http://www.b-eye-network.com/view/257)
Monday, April 03, 2006
The Role of Open Source in Enterprise Portals by Colin White
When evaluating open-source solutions there are four main areas to consider: features provided, development effort, product cost and support.
An enterprise portal has evolved to become the technology of choice for providing users with a single web workspace for handling and managing all of the business information and content they need to do their jobs. Companies evaluating and deploying an enterprise portal have a wide range of product options to choose from. They can buy an independent best-of-breed portal that works in a number of software environments, or they can use portal capabilities that have been integrated into software solutions such as web application servers, integration software, packaged applications, content management systems and business intelligence tools.
A third option is to build a custom enterprise portal in-house. One starting point for a custom-built portal is a commercial or open-source web HTTP server such as Apache. The problem with this approach is that without a significant amount of development work, the result is likely to offer little more than that provided by a corporate intranet or extranet. Key features such as publishing, search, categorization, personalization, single sign-on, etc., are usually missing from portals that are custom built using a web HTTP server as a foundation.
Another option for custom building a portal is to use an open-source portal solution. Many open-source portals provide not only the key portal features outlined above, but also other capabilities such as content management and collaboration. My objective in this month’s newsletter is to take a quick look at open-source portal products, and review the pros and cons of using them.
When evaluating open-source solutions there are four main areas to consider: features provided, development effort, product cost and support. I suspect the last two—product cost and support—may puzzle you. After all isn’t open source free? When I gave a presentation on the topic of open-source portals at a recent conference, I split so-called open-source portal products into three categories. The first category consisted of products that were being offered free of charge, but the organization offering them made its money by offering fee-based support and consulting. The second category consisted of products where license fees could be offset by contributing extensions back to the organization authoring the product. The third category contained products with no license fees and no support other than provided by the community of users who were developing and/or deploying the product. I guess, strictly speaking, only the third category is really open source.
Some people at the conference commented that they would have liked more details about the open-source licenses for each of the products. As I result, when I started writing this newsletter I decided to take a more detailed look at this topic. I quickly learnt that this subject was quite a mine field and could become the subject of several newsletters, or even a book! Suffice it to say that if you are going to develop an enterprise portal using an open-source product, take a close look at the license. You need to consider issues like whether the license can be revoked or whether you have to make code modifications public. Two points to note before I take a quick look at some of the open-source products. The first is that most of them are designed for a Java environment, rather than for the Microsoft .NET platform. The second is that there are some very good web sources on the topic of open-source portals. One blog I like here is: Manageability - Open Source Portals Written in Java.
There are a considerable number of open-source portal products, but four that demonstrate the type of capabilities offered are: Liferay, Jahia, Gluecode and Pluto.
Liferay is a portal made available under the MIT license, which is similar to the Apache and BSD licenses. It includes a web content manager, provides a connector for Yale’s single sign-on engine, has internationalization and personalization, and supports both the JSR 168 and WSRP portal standards. It is both DBMS and application server agnostic. The Liferay organization creates revenue through custom development, and product support and training.
Jahia is an integrated portal server and content manager. It is made available under a collaborative source license, i.e., a pay or contribute your enhancements model. It places strong emphasis on content management and supports internationalization, content workflow, versioning, WebDAV and web services, and is integrated with the Apache Lucene Search engine. Jahia Solutions is the founder, the official maintainer and also the major contributor to the Jahia project. Like Liferay, Jahia Solutions provides both development and training services.
Gluecode SE is a free Java-certified application platform and portal framework. Product support is available on an annual subscription basis. It uses Apache-based technologies including the Apache Geronimo application server, the Apache Derby integrated Java DBMS (contributed by IBM and based on the Cloudscape DBMS, which was acquired from Informix), and the Apache Pluto portal framework. GlueCode Software was acquired by IBM in May of this year. IBM’s positioning of the acquisition is that “customers and business partners can tap into the low cost of entry of open-source technology to quickly develop and deploy applications, and migrate to WebSphere software as business needs expand.” Note that this acquisition demonstrates how the status of “open source” software can change.
Pluto is one of several portals offered by the Apache Software Foundation. Others include Jetspeed-1 and JetSpeed-2 and WSRP-4J. Pluto is a reference implementation (provided by IBM) of the Java Portlet Specification (JSR 168). Pluto serves as portlet container that implements JSR 168 and offers developers a working platform from which they can test their portlets. Pluto only supports the portlet container and the JSR 168 specification. In contrast, the more sophisticated, JetSpeed project concentrates on the portal itself, rather than the portlet container.
In addition to the four products discussed above, it is also worth mentioning that universities and educational bodies are also working together to create open-source portal-related solutions. Projects here include uPortal and Sakai.
As you can see, there is a lot of activity in the area of open-source portals. The use of these products often involves trading off license fees for development effort. Many of these products require significant development and support effort. This effort varies by product, however, and to be fair many products do contain some very useful and usable capabilities. Even if you don’t intend to put an open-source portal into production, it may be useful for education purposes, prototyping and in some cases for testing whether your program code meets portal standards such as the JSR 168 Java portlet API specification or the OASIS Web Services for Remote Portlets (WSRP) specification.
(http://www.b-eye-network.com/view/1016)
An enterprise portal has evolved to become the technology of choice for providing users with a single web workspace for handling and managing all of the business information and content they need to do their jobs. Companies evaluating and deploying an enterprise portal have a wide range of product options to choose from. They can buy an independent best-of-breed portal that works in a number of software environments, or they can use portal capabilities that have been integrated into software solutions such as web application servers, integration software, packaged applications, content management systems and business intelligence tools.
A third option is to build a custom enterprise portal in-house. One starting point for a custom-built portal is a commercial or open-source web HTTP server such as Apache. The problem with this approach is that without a significant amount of development work, the result is likely to offer little more than that provided by a corporate intranet or extranet. Key features such as publishing, search, categorization, personalization, single sign-on, etc., are usually missing from portals that are custom built using a web HTTP server as a foundation.
Another option for custom building a portal is to use an open-source portal solution. Many open-source portals provide not only the key portal features outlined above, but also other capabilities such as content management and collaboration. My objective in this month’s newsletter is to take a quick look at open-source portal products, and review the pros and cons of using them.
When evaluating open-source solutions there are four main areas to consider: features provided, development effort, product cost and support. I suspect the last two—product cost and support—may puzzle you. After all isn’t open source free? When I gave a presentation on the topic of open-source portals at a recent conference, I split so-called open-source portal products into three categories. The first category consisted of products that were being offered free of charge, but the organization offering them made its money by offering fee-based support and consulting. The second category consisted of products where license fees could be offset by contributing extensions back to the organization authoring the product. The third category contained products with no license fees and no support other than provided by the community of users who were developing and/or deploying the product. I guess, strictly speaking, only the third category is really open source.
Some people at the conference commented that they would have liked more details about the open-source licenses for each of the products. As I result, when I started writing this newsletter I decided to take a more detailed look at this topic. I quickly learnt that this subject was quite a mine field and could become the subject of several newsletters, or even a book! Suffice it to say that if you are going to develop an enterprise portal using an open-source product, take a close look at the license. You need to consider issues like whether the license can be revoked or whether you have to make code modifications public. Two points to note before I take a quick look at some of the open-source products. The first is that most of them are designed for a Java environment, rather than for the Microsoft .NET platform. The second is that there are some very good web sources on the topic of open-source portals. One blog I like here is: Manageability - Open Source Portals Written in Java.
There are a considerable number of open-source portal products, but four that demonstrate the type of capabilities offered are: Liferay, Jahia, Gluecode and Pluto.
Liferay is a portal made available under the MIT license, which is similar to the Apache and BSD licenses. It includes a web content manager, provides a connector for Yale’s single sign-on engine, has internationalization and personalization, and supports both the JSR 168 and WSRP portal standards. It is both DBMS and application server agnostic. The Liferay organization creates revenue through custom development, and product support and training.
Jahia is an integrated portal server and content manager. It is made available under a collaborative source license, i.e., a pay or contribute your enhancements model. It places strong emphasis on content management and supports internationalization, content workflow, versioning, WebDAV and web services, and is integrated with the Apache Lucene Search engine. Jahia Solutions is the founder, the official maintainer and also the major contributor to the Jahia project. Like Liferay, Jahia Solutions provides both development and training services.
Gluecode SE is a free Java-certified application platform and portal framework. Product support is available on an annual subscription basis. It uses Apache-based technologies including the Apache Geronimo application server, the Apache Derby integrated Java DBMS (contributed by IBM and based on the Cloudscape DBMS, which was acquired from Informix), and the Apache Pluto portal framework. GlueCode Software was acquired by IBM in May of this year. IBM’s positioning of the acquisition is that “customers and business partners can tap into the low cost of entry of open-source technology to quickly develop and deploy applications, and migrate to WebSphere software as business needs expand.” Note that this acquisition demonstrates how the status of “open source” software can change.
Pluto is one of several portals offered by the Apache Software Foundation. Others include Jetspeed-1 and JetSpeed-2 and WSRP-4J. Pluto is a reference implementation (provided by IBM) of the Java Portlet Specification (JSR 168). Pluto serves as portlet container that implements JSR 168 and offers developers a working platform from which they can test their portlets. Pluto only supports the portlet container and the JSR 168 specification. In contrast, the more sophisticated, JetSpeed project concentrates on the portal itself, rather than the portlet container.
In addition to the four products discussed above, it is also worth mentioning that universities and educational bodies are also working together to create open-source portal-related solutions. Projects here include uPortal and Sakai.
As you can see, there is a lot of activity in the area of open-source portals. The use of these products often involves trading off license fees for development effort. Many of these products require significant development and support effort. This effort varies by product, however, and to be fair many products do contain some very useful and usable capabilities. Even if you don’t intend to put an open-source portal into production, it may be useful for education purposes, prototyping and in some cases for testing whether your program code meets portal standards such as the JSR 168 Java portlet API specification or the OASIS Web Services for Remote Portlets (WSRP) specification.
(http://www.b-eye-network.com/view/1016)

Bug-Eating Robots Use Flies for Fuel by Sean Markey
At the Bristol Robotics Laboratory in England, researchers are designing their newest bug-eating robot—Ecobot III.
The device is the latest in a series of small robots to emerge from the lab that are powered by a diet of insects and other biomass.
We all talk about robots being able to do stuff on their own, being intelligent and autonomous," said lab director Chris Melhuish.
"But the truth of the fact is that without energy, they can't do anything at all."
Most robots today draw that energy from electrical cords, solar panels, or batteries. But in the future some robots will need to operate beyond the reach of power grids, sunlight, or helping human hands.
Melhuish and his colleagues think such release-and-forget robots can satisfy their energy needs the same way wild animals do—by foraging for food.
"Animals are the proof that this is possible," he said.
Bug-munching Bots
Over the last decade, Melhuish's team has produced a string of bots powered by sugar, rotten apples, or dead flies.
The biomass is converted into electricity through a series of stomachlike microbial fuel cells, or MFCs.
Living batteries, MFCs generate power from colonies of bacteria that release electrons as the microorganisms digest plant and animal matter. (Electricity is simply a flow of electrons.)
The lab's first device, named Slugbot, was an artificial predator that hunted for common garden slugs.
While Slugbot never digested its prey, it laid the groundwork for future bots powered by biomass.
In 2004 researchers unveiled Ecobot II. About the size of a dessert plate, the device could operate for 12 days on a diet of eight flies.
"The flies [were] given as a whole insect to each of the fuel cells on board the robot," said Ioannis Ieropoulos, who co-developed Ecobot II as part of his Ph.D. research.
With its capacitors charged, the bot could roll 3 to 6 inches (8 to 16 centimeters) an hour, moving toward light while recording temperature. It sent data via a radio transmitter.
While hardly a speedster, Ecobot II was the first robot powered by biomass that could sense its world, process it, act in it, and communicate, Melhuish says.
The scientist sees analogs in the autonomously powered robots of the future.
"If you really do want robots that are going to … monitor fences, [oceans], pollution levels, or carbon dioxide—all of those things—what you need are very, very cheap little robots," he said.
"Now our robots are quite big. But in 20 to 30 years time, they could be quite minuscule."
(See a photo of small, solar-powered robots.)
More Power
Whether microbial fuel-cell technology can advance enough to power those robots, however, is unclear.
Stuart Wilkinson, a mechanical engineer at the University of South Florida in Tampa, developed the world's first biomass-powered robot, a toy-train-like bot nicknamed Chew-Chew that ran on sugar cubes.
He says the major drawback of MFCs is that it takes a big fuel cell to produce a small amount of power.
Most AA batteries, for example, produce far more power than a single MFC.
"MFCs are capable of running low-power electronics, but are not well suited to power-hungry motors needed for machine motion," Wilkinson said in an email interview.
He added that scientists "need to develop MFC technology further before it can be of much practical use for robot propulsion."
Ieropoulos, Ecobot II's co-developer, agrees that MFCs need a power boost.
He and his colleagues are exploring ways to improve the materials used in MFCs and to maintain resident microbes at their peak.
Bot Weaning
To date, the Bristol team has hand-fed its bots.
But if the researchers are going to realize their vision of autonomously powered robots, then the machines will need to start gathering their own food.
When Ecobot II debuted in 2004, Melhuish suggested one way that it might lure and capture its fly food-source: a combination fly-trap/suction pump baited with pheromones.
Whether the accessory will appear in Ecobot III is anyone's guess. The BRL team remains tight-lipped about their current project, preferring to finish their work in secret before discussing it publicly.
Melhuish will say this, however: "What we've got to do is develop a better digestion system … . There are many, many problems that have to be overcome, and waste removal is one of them."
Will the future bring robot restrooms? Watch this space.
(http://news.nationalgeographic.com/news/2006/03/0331_060331_robot_flesh.html)
The device is the latest in a series of small robots to emerge from the lab that are powered by a diet of insects and other biomass.
We all talk about robots being able to do stuff on their own, being intelligent and autonomous," said lab director Chris Melhuish.
"But the truth of the fact is that without energy, they can't do anything at all."
Most robots today draw that energy from electrical cords, solar panels, or batteries. But in the future some robots will need to operate beyond the reach of power grids, sunlight, or helping human hands.
Melhuish and his colleagues think such release-and-forget robots can satisfy their energy needs the same way wild animals do—by foraging for food.
"Animals are the proof that this is possible," he said.
Bug-munching Bots
Over the last decade, Melhuish's team has produced a string of bots powered by sugar, rotten apples, or dead flies.
The biomass is converted into electricity through a series of stomachlike microbial fuel cells, or MFCs.
Living batteries, MFCs generate power from colonies of bacteria that release electrons as the microorganisms digest plant and animal matter. (Electricity is simply a flow of electrons.)
The lab's first device, named Slugbot, was an artificial predator that hunted for common garden slugs.
While Slugbot never digested its prey, it laid the groundwork for future bots powered by biomass.
In 2004 researchers unveiled Ecobot II. About the size of a dessert plate, the device could operate for 12 days on a diet of eight flies.
"The flies [were] given as a whole insect to each of the fuel cells on board the robot," said Ioannis Ieropoulos, who co-developed Ecobot II as part of his Ph.D. research.
With its capacitors charged, the bot could roll 3 to 6 inches (8 to 16 centimeters) an hour, moving toward light while recording temperature. It sent data via a radio transmitter.
While hardly a speedster, Ecobot II was the first robot powered by biomass that could sense its world, process it, act in it, and communicate, Melhuish says.
The scientist sees analogs in the autonomously powered robots of the future.
"If you really do want robots that are going to … monitor fences, [oceans], pollution levels, or carbon dioxide—all of those things—what you need are very, very cheap little robots," he said.
"Now our robots are quite big. But in 20 to 30 years time, they could be quite minuscule."
(See a photo of small, solar-powered robots.)
More Power
Whether microbial fuel-cell technology can advance enough to power those robots, however, is unclear.
Stuart Wilkinson, a mechanical engineer at the University of South Florida in Tampa, developed the world's first biomass-powered robot, a toy-train-like bot nicknamed Chew-Chew that ran on sugar cubes.
He says the major drawback of MFCs is that it takes a big fuel cell to produce a small amount of power.
Most AA batteries, for example, produce far more power than a single MFC.
"MFCs are capable of running low-power electronics, but are not well suited to power-hungry motors needed for machine motion," Wilkinson said in an email interview.
He added that scientists "need to develop MFC technology further before it can be of much practical use for robot propulsion."
Ieropoulos, Ecobot II's co-developer, agrees that MFCs need a power boost.
He and his colleagues are exploring ways to improve the materials used in MFCs and to maintain resident microbes at their peak.
Bot Weaning
To date, the Bristol team has hand-fed its bots.
But if the researchers are going to realize their vision of autonomously powered robots, then the machines will need to start gathering their own food.
When Ecobot II debuted in 2004, Melhuish suggested one way that it might lure and capture its fly food-source: a combination fly-trap/suction pump baited with pheromones.
Whether the accessory will appear in Ecobot III is anyone's guess. The BRL team remains tight-lipped about their current project, preferring to finish their work in secret before discussing it publicly.
Melhuish will say this, however: "What we've got to do is develop a better digestion system … . There are many, many problems that have to be overcome, and waste removal is one of them."
Will the future bring robot restrooms? Watch this space.
(http://news.nationalgeographic.com/news/2006/03/0331_060331_robot_flesh.html)
Portals Fostering Open-Source Success By Jim Rapoza
If you go to the open-source development site sourceforge.net and search on the term "portal," you'll get hundreds of hits. In fact, you could reasonably argue that, when it comes to open-source enterprise applications, portals have been the biggest success story.
In addition to being highly effective and capable on their own, open-source portals have served to demonstrate the effectiveness of other open-source technologies, especially the MySQL database and the PHP scripting language. This is clearly illustrated in probably the most popular open-source portal application, PHP-Nuke (www.phpnuke.org), which is easily customized and includes pretty much any feature you would want from a portal, including content and document management, forums, chat, and blogging. PHP-Nuke has spawned additional open-source portals, including PostNuke (www.postnuke.com).
Portals of comparable quality based on other platforms are fewer and farther between, but you won't have to look too hard.
Many very good open-source portals are based on JavaServer technology, including Liferay LLC's Liferay Portal (www.liferay.com), Magnolia (www.magnolia.info) and The Exo Platform SARL's Exo Platform 1.0. Perhaps surprisingly, there are also many good open-source portals based on Microsoft Corp.'s .Net platform. One excellent example is DotNetNuke (www.dotnetnuke.com). Even the venerable Perl language has portal applications, such as the code that runs the popular Slashdot site.
Click here to read Labs' review of Exo Platform 1.0.
And we would be remiss if we didn't mention one of the best open-source portal options available, a product that has garnered eWEEK Labs Analyst's Choice recognition: Plone (www.plone.org), which is based on the Python language and Zope Corp.'s Zope application server.
The list could go on and on, with many excellent portal applications working on almost any platform and on any language. And many of these aren't simply proof-of-concept but can be found running many business sites and on large company intranets. A quick search through the user lists of many open-source portal applications reveals government agencies, nonprofit organizations and very large businesses using open-source portals for core activities and sites.
In addition, while some of these open-source portals are on the small, individual developer side of the open-source movement, many have a company backing the application and have multiple professional consultants and integrators trained on deploying and supporting the open-source portal platform.
Companies no longer have to fear going it alone with an open-source application; instead, they can get the type of support and reliability they have come to expect from commercial vendors.
(http://www.eweek.com)
In addition to being highly effective and capable on their own, open-source portals have served to demonstrate the effectiveness of other open-source technologies, especially the MySQL database and the PHP scripting language. This is clearly illustrated in probably the most popular open-source portal application, PHP-Nuke (www.phpnuke.org), which is easily customized and includes pretty much any feature you would want from a portal, including content and document management, forums, chat, and blogging. PHP-Nuke has spawned additional open-source portals, including PostNuke (www.postnuke.com).
Portals of comparable quality based on other platforms are fewer and farther between, but you won't have to look too hard.
Many very good open-source portals are based on JavaServer technology, including Liferay LLC's Liferay Portal (www.liferay.com), Magnolia (www.magnolia.info) and The Exo Platform SARL's Exo Platform 1.0. Perhaps surprisingly, there are also many good open-source portals based on Microsoft Corp.'s .Net platform. One excellent example is DotNetNuke (www.dotnetnuke.com). Even the venerable Perl language has portal applications, such as the code that runs the popular Slashdot site.
Click here to read Labs' review of Exo Platform 1.0.
And we would be remiss if we didn't mention one of the best open-source portal options available, a product that has garnered eWEEK Labs Analyst's Choice recognition: Plone (www.plone.org), which is based on the Python language and Zope Corp.'s Zope application server.
The list could go on and on, with many excellent portal applications working on almost any platform and on any language. And many of these aren't simply proof-of-concept but can be found running many business sites and on large company intranets. A quick search through the user lists of many open-source portal applications reveals government agencies, nonprofit organizations and very large businesses using open-source portals for core activities and sites.
In addition, while some of these open-source portals are on the small, individual developer side of the open-source movement, many have a company backing the application and have multiple professional consultants and integrators trained on deploying and supporting the open-source portal platform.
Companies no longer have to fear going it alone with an open-source application; instead, they can get the type of support and reliability they have come to expect from commercial vendors.
(http://www.eweek.com)
Subscribe to:
Posts (Atom)