Explore the parallel Web
Can you present two formats with one data source?
In this series of articles, we present a thorough, example-filled examination of the existing and emerging technologies that enable machines and humans to easily access the wealth of Web-published data. In this article, we examine the concept of the parallel Web and look at two techniques that Web content publishers use to put both human-readable and machine-consumable content on the Web: the HTML link element and HTTP content negotiation. With these two techniques, content consumers can choose among a variety of different formats of the data on a Web page. Review the history of the techniques and how they are currently deployed on the Web, and how you might use the parallel Web to integrate calendar, banking, and photo data within an example scenario, MissMASH. Finally, we evaluate the parallel Web and determine that, while these techniques are mature and widely deployed, there are disadvantages to separating machine-readable data from the corresponding human-readable content.
");
}
}
}
//-->
In this article, we will cover our notion of the parallel Web. This term refers to the techniques that help content publishers represent data on the Web with two or more addresses. For example, one address might hold a human-consumable format and another a machine-consumable format. Additionally, we include within the notion of the parallel Web those cases where alternate representations of the same data or resource are made available at the same location, but are selected through the HTTP protocol (see Resources for links to this and other material).
HTTP and HTML are two core technologies that enable the World Wide Web, and the specifications of each contain a popular technique that enables the discovery and negotiation of alternate content representations. Content negotiation is available through the HTTP protocol, the mechanism that allows user agents and proxies/gateways on the Internet to exchange hypermedia. This technique might be mapped mostly to a scenario where alternate representations are found at the same Web address. In HTML pages, the link element indicates a separate location containing an alternate representation of the page. In the remainder of this article, we'll look at some of the history behind these two techniques, examine their current deployment and usage today, explain how they might be applied to help solve the MissMASH example scenario, and evaluate the strengths, weaknesses, and appropriate use cases for both.
");
}
}
}
//-->
In this article, we will cover our notion of the parallel Web. This term refers to the techniques that help content publishers represent data on the Web with two or more addresses. For example, one address might hold a human-consumable format and another a machine-consumable format. Additionally, we include within the notion of the parallel Web those cases where alternate representations of the same data or resource are made available at the same location, but are selected through the HTTP protocol (see Resources for links to this and other material).
HTTP and HTML are two core technologies that enable the World Wide Web, and the specifications of each contain a popular technique that enables the discovery and negotiation of alternate content representations. Content negotiation is available through the HTTP protocol, the mechanism that allows user agents and proxies/gateways on the Internet to exchange hypermedia. This technique might be mapped mostly to a scenario where alternate representations are found at the same Web address. In HTML pages, the link element indicates a separate location containing an alternate representation of the page. In the remainder of this article, we'll look at some of the history behind these two techniques, examine their current deployment and usage today, explain how they might be applied to help solve the MissMASH example scenario, and evaluate the strengths, weaknesses, and appropriate use cases for both.
The techniques necessary to weave a parallel Web have been available almost since the inception of the World Wide Web itself, and they were codified within the original HTTP/1.0 and HTML 1.0 specifications. However, even today their deployment, implementation, and usage varies. For example, the Apache Web server is the most widely used HTTP server on the Internet today (see Resources) and has had support for content negotiation for almost ten years. But few sites actually include content negotiation configurations and alternate representations of resources. In contrast, the number of Web pages that use the link element to point to alternate representations of pages has grown exponentially, especially with the advent of online journals and Weblogs. Let us briefly examine the origins of these two techniques so as to better understand how they have evolved and helped create a meaningful Web for both humans and machines.
Since the Web was conceived for access by humans across the globe and from all walks of life, it had to provide mechanisms to access hypermedia in a wide variety of languages, character sets, and media types. For example, a visually impaired individual might configure his user agent (his Web browser, usually) to prefer plain text representations of images on Web pages. The plain-text representation would contain information that described the image and that could be used by screen reading software, possibly including details such as the location, names of individuals, or dates. On the other hand, a standard Web browser intended for sighted individuals would request image resources as specific image media types that the browser is capable of rendering (image/png or image/jpeg, for instance). The potential use cases for alternate encodings of information on the Web are as diverse as the populations of human beings served by the Web, and the HTTP specification recognizes this and provides content negotiation to address it.
Content negotiation as a phrase did not appear until the completion of the HTTP/1.1 specification, but the core of its functionality was defined in the HTTP/1.0 specification (see Resources for links to both) -- albeit in a rather underspecified format. The HTTP/1.0 specification provided implementors with a small set of miscellaneous headers: Accept, Accept-Charset, Accept-Encoding, Accept-Language, and Content-Language. (We will go into more technical detail of these headers and their usage in the next section of this article.)
Historically, it is important to note that in its original form, the content negotiation mechanism left it completely up to the server to choose the best representation from all of the combinations available given by the choices sent by the user agent. In the next (and current) version of content negotiation, which arrived with HTTP/1.1, the specification introduced choices with respect to who makes the final decision on the alternate representation's format, language, and encoding. The specification mentions server-driven, agent-driven, and transparent negotiation.
Server-driven negotiation is very similar to the original content negotiation specification, with some improvements. Agent-driven negotiation is new and allows the user agent (possibly with help from the user) to choose the best representation out of a list supplied by the server. This option suffers from underspecification and the need to issue multiple HTTP requests to the server to obtain a resource; as such, it really hasn't taken off in current deployments. Lastly, transparent negotiation is a hybrid of the first two types, but is completely undefined and hence is also not used on the Web today.
Amidst this sea of underspecification, however, HTTP/1.1 introduced quality values: floating point numbers between 0 and 1 that indicate the user agent's preference for a given parameter. For example, the user agent might use quality values to indicate to the server its user's fluency level in several languages. The server could then use that information along with the faithfulness of its alternate language representations to choose the best translation for that request and deliver it as per server-driven content negotiation.
The examples you've seen of content negotiation so far have highlighted its uses to serve the heterogeneous mix of people accessing the World Wide Web. But just as diverse humans can use content negotiation to retrieve Web content in a useful fashion, so also can diverse software programs request content in machine-readable formats to further their utility on the Web. You will see how to use content negotiation to further a meaningful Web for humans and machines later in this article.
As with content negotiation, the link element has gone through some evolutionary stages in order to meet the requirements for a parallel Web. In the first stages of the HTML specification, the link element only possessed a small number of attributes, which mainly served to indicate the relationship between the current page and the location of the resource to which the element's href attribute refers. Most of these relationships were originally designed for navigational functionality, but the link element's relationships were always meant to be extensible. Although the semantics and governance of these relationships had never been clearly defined officially, their usage has exploded in recent years. There's even now a process and a site at Internet Assigned Numbers Authority (IANA) to register new relationships (see Resources).
Most notably, the HTML 4.01 specification introduced new attributes that can indicate the media type and character set of the resource referenced by the link element. It is thanks to these additions that the link element has received wider adoption, especially by Weblogs. Later in this article, you will see that while many of the traditional use cases for the link element revolve around the needs of humans, the element is increasingly used to reference machine-consumable content in an attempt to further software's capabilities on the Web.
Back to top
To start, look at a series of example uses of the link element and see how its usage has evolved over time to provide machines with more accurate access to the data encoded in HTML pages. Listing 1 uses three of the standard link relationships defined within the HTML 4.01 specification (see Resources for all available link types) to give navigational hints to Web page readers. If publishers were to include this additional metadata in their pages, navigating certain types of documents, such as articles, books, or help manuals, would be much easier than the typical situation today, where users must fish for an anchor link, possibly labeled next, or possibly labeled something completely different.Listing 1. Navigational link elements
"http://www.w3.org/TR/html4/strict.dtd">
...the rest of the article...
In Listing 2, you see the most popular use of the link element today. Most modern browsers have a decent amount of support for the Cascading Style Sheets specifications, allowing publishers to separate structure from presentation in their HTML pages and making it easier to change their visual presentation without having to recode the entire page. This example in Listing 2 makes use of a new attribute: media, which specifies the intended destination medium for the associated style information. The default value is screen, but you can also use print, or, to target mobile devices, handheld. (See Resources for more on these values.) Beware: while you can use multiple values in the media attribute, they must be separated by commas, as opposed to the spaces you'd use for values of the rel attribute.Listing 2. Providing links to stylesheet information
media="screen,print"
type="text/css"
href="../dw.css">
...the rest of the article...
Our next example uses the internationalization capabilities of the HTML specification to give browsers or user agents language-specific navigational information in order to best match the reader with her preferred tongue. In the case of this article series, the authors combined can speak two languages fluently. If we had a large Spanish readership, we could provide those readers with a link to the article in Spanish by using the link element.
Notice a few of the attributes and their values that we use in Listing 3. First, we use the alternate link type to express the relationship between this article and our Spanish version. Because we are using it in combination with the hreflang attribute, we imply that the referenced Web page is a translated, alternate version of the current document. We also add a lang attribute to specify the language of the title attribute. Finally, we added a type attribute value, which is optional and is only there as an advisory hint to the user agent. (A Web browser might use this hint, for example, to launch the registered application that can deal with the specified media type.)Listing 3. Language-specific navigational link elements
lang="es"
title="La Red Paralela"
type="text/html"
hreflang="es"
href="es/redparalela.html">
...the rest of the article...
The previous examples mostly served to show the most common uses of the link element, but, with the exception of the language-specific use of link, they didn't really show you how to provide alternate representations of the data found on the original page. And even in the language example given in Listing 3, the alternate representation is intended for consumption by humans and not by machines. The final link example in Listing 4 shows how blogs use the link element to refer to feeds. A feed is an XML representation of its HTML counterpart that carries more structured semantics than the HTML contents of a blog as rendered for a person. Blog-reading software can easily digest an XML feed in order to group blog entries by categories, dates, or authors, and to facilitate powerful search and filter functionality. Without the link element, software would not auto-discover a machine-readable version of a blog's contents and could not provide this advanced functionality. This is a good example of how content generated by humans (even through blog publishing tools) is not easily understood by machines without the use of a parallel Web technique. The feed auto-discovery mechanism enabled by the link element helps humans co-exist with machines on the Web.
In Listing 4, you begin to see the power of the link element emerge to provide machines with valuable information in decoding content on the Web today. We again use of the "alternate" relationship to denote a new URLwhere you can find a substitute representation of the same content currently viewed. Through the use of media types, we can give the user agent the ability to choose the best understood format -- whether it be Atom or RSS feeds or any other media format.
The link elements shown in Listing 4 create a parallel Web with three nodes. First, at the current URL is an HTML representation of this article intended for human consumption. Second, the relative URL ../feed/atom contains a machine-readable version of the same content represented in the application/atom+xml format. And finally, the relative URL ../feed/rss contains a different machine-readable version of the same content, represented this time in the application/rdf+xml format.Listing 4. Providing auto-discovery links to feed URLs in blogs
title="Atom 1.0 Feed"
type="application/atom+xml"
href="../feed/atom">
title="RSS Feed"
type="application/rdf+xml"
href="../feed/rss">
...the rest of the article...
We must note that the values of the rel attributes are not limited to a closed set; the Web community is constantly experimenting with new values that eventually become the de facto standard in expressing a new relationship between the HTML page and the location specified in the href attribute. For instance, the pingback value used by the WordPress blog publishing system (see Resources) is now very widely used; it provides machines with a pointer to a service endpoint that connects Weblog entries with one another through their comment listings.
As simple REST-based Web services permeate the Web, we foresee a large number of rel values being defined to point to many different service interfaces. Such an explosion of uses for the link element greatly enhances the functionality of traditional Web browsers but also comes with other problems involving governance and agreement of relationship types that are beyond the scope of this article. Find more information on the HTML link element in Resources.
Back to top
We will cover content negotiation in somewhat less detail than the link element because of its possible complexity, but we'll go into enough detail to illustrate how it is used to create a parallel Web. In this discussion, we will focus on how content negotiation is configured using the popular Apache HTTP Web server software. Other Web server software works similarly, and the underlying concepts are the same.
Typically on the Web, URLs contain a file extension that indicate either the method used to produced the HTML (for example, .html for static pages, .php for PHP scripts, or .cgi for various scripting languages using the Common Gateway Interface) or the media format of the content at the URL (such as .png, .pdf, or .zip). While this approach is adequate in many cases, it requires that you create and maintain one URL for each different representation of the same content. In turn, this requires that you use some mechanism to link the multiple URLs together (such as the HTML link element described above, or the human-traversable a anchor link element) and that software know how to choose between the different URLs according to its needs.
Content negotiation allows different representations of data to be sent in response to a request for a single URL, depending on the media types, character sets, and languages a user agent indicates that it can (and wants to) handle. Whereas the link element constructs a parallel Web by assigning multiple URLs to multiple representations of the same content, content negotiation enables a parallel Web wherein multiple formats of the same content all are available at a single URL. The Resources in this article contain links to more detail on behind-the-scenes HTTP content negotiation.
Apache provides a content negotiation module that has two methods to select resource variants depending on the HTTP request: type maps and MultiViews. If a type map is used in the Apache configuration file, it is used to map URLs to file names based on any combination of language, content type, and character encoding. MultiViews are very similar, except that the administrator does not have to create a type map file; instead, the map is created on the fly based on other configurations specified throughout the server configuration document. For brevity, in this article we will only show an example of a type map, but please see the Resources for links to very detailed Apache content negotiation guides.
In Listing 5, we list the contents of a type map used to provide the mapping necessary to serve different versions of our article based on language and media type. In line 1, we specify the single URI used to serve multiple format and language representations of the same article. Lines 3 and 4 establish that by default we will serve the file parallelweb.en.html in response to all requests for the text/html media type. In lines 6 through 9, we have a special case in which we can serve the Spanish version of our article if desired by the user agent. Next, in lines 10 and 11, we provide a printed version of our article. Finally, you see in lines 13 and 14 the ability for software to retrieve an Atom feed version of our article. Content negotiation allows blog-reading software requesting our article in the application/atom+xml content type to receive a representation of the article that the software can understand more easily than the standard HTML version.Listing 5. Using type maps in Apache to serve multiple language and format representations
[1] URI: parallelweb
[2]
[3] URI: parallelweb.en.html
[4] Content-type: text/html
[5]
[6] URI: parallelweb.es.html
[7] Content-type: text/html
[8] Content-language: es
[9]
[10] URI: parallelweb.ps
[11] Content-type: application/postscript; qs=0.8
[12]
[13] URI: parallelweb.xml
[14] Content-type: application/atom+xml
In summary, this extra configuration on our server allows a single URL to be distributed for our article, while still permitting both human-friendly and machine-readable data to be available as long as the user agent requests it.
Now, let's move on to our example application and hypothesize how we might build it by using parallel Web techniques.
Back to top
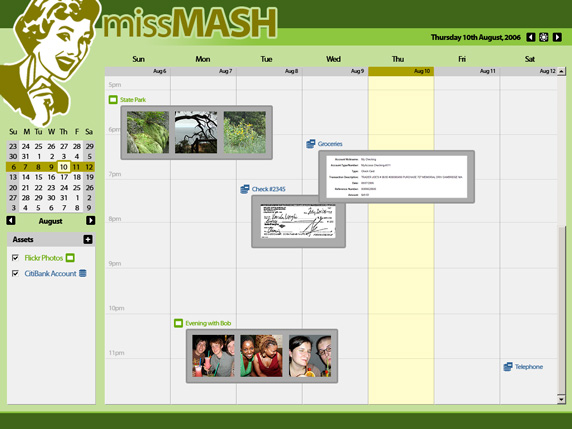
In our series overview (see Resources for a link), we proposed an example application called MissMASH that would illustrate the different techniques covered in the series. The application's ultimate goal is for the user to gain access to personal information hosted in different locations, all displayed using a calendar-based interface. Photographs could be hosted on Flickr, online banking statements could come from Citibank, and scheduling details from Google Calendar. (See Resources for links to all three.) Our focus is not to walk you through actual running code for this application, but to highlight the main mechanisms that would facilitate the building of such an application using software not managed by any of the hosting providers of our sample data.
Please keep in mind that parts of our scenario will be, by necessity, fictitious due to the mere fact that not all of our sample data providers employ the techniques covered in this series. The location of the software that powers MissMASH does not matter either. It could be written as a traditional server-side Web application using any Web application framework du jour, or it could be a Web-based client-side application, making use of Ajax (the newly rediscovered XML HTTP request JavaScript object; see Resources) techniques to compose the data. In any case, the key to this kind of application -- and the key question that we are asking -- is how MissMASH finds, identifies, and uses the information necessary to accomplish its purpose. Ideally, the less information it needs from the (human) user, the better. Let's see how the parallel Web might allow us to build MissMASH.
One of the very first pieces of information needed by MissMASH is some sort of online calendar account information. As you might imagine, this might become unwieldy in no time if we required MissMASH to understand every possible public and/or private calendar service on the Internet. But if these services make use of parallel Web techniques, it is as simple as entering the URL you see in your browser when accessing that service into MissMASH. Consider, for example, Google Calendar. (For the purposes of this example, we'll ignore user authentication details.) Imagine that a user configuring MissMASH navigates in a Web browser to his Google Calendar. Once there, he copies the URL in his browser's address bar and pastes it into the MissMASH configuration. MissMASH would request that URL, parse the returned HTML, and find inside a gem of the parallel Web: a link element.
Google offers multiple versions of its online calendar: iCalendar (see Resources), Atom feeds, and HTML. Unfortunately, it only provides a link element to the Atom feed version of the calendar, but it's just as described in Listing 4. The same would occur for Flickr, which happens to also provide a link to an Atom feed of your most recent photos. In either case, MissMASH would get a second URL from the href attribute of the link element and would resolve that URL to receive a machine-readable representation of the user's event and photo information. Because these representations contain (among other data) dates and locations that software can easily recognize, MissMASH can use these alternate representations to render calendar and photo data together.
For illustrative purposes, let's also imagine that Citibank used content negotiation on the user's account URL. MissMASH can then negotiate with the Citibank server for any of the different supported formats, such as Atom feeds or the Quicken Interchange Format (see Resources)
We now have almost all of the information necessary to render our external personal data sources in MissMASH. Of course, for MissMASH to use the parallel Web in this way, it must understand both the structure and the semantics of the machine-readable representations that it retrieves. If MissMASH receives iCal data from Google Calendar, an Atom feed from Flickr, and Quicken Interchange Format data from Citibank, then it must understand how to parse and interpret all three of these machine-readable formats in order to merge the information. The parallel Web techniques do not themselves help resolve this matter; instead, the parallel Web's key benefit is that the user does not have to visit obscure configuration Web pages of the source-data services to find the URLs to one of the data formats supported by MissMASH. While MissMASH must focus on supporting a small number of different formats, this is far superior to requiring MissMASH to understand both a variety of data formats and a variety of application-specific, human-intended services for retrieving that data.
Future articles in this series will examine techniques to create a meaningful Web that impose a smaller burden on the data consumer to understand multiple machine-readable formats.
Back to top
As with most things on the Web, our conclusions about the evaluation categories we discuss in this section will not be clear cut. There are no black-and-white answers, which is why such a multitude of competing and complementary techniques exists. However, we will try our best to help you understand the reasoning behind our evaluation in order to understand what is required for machines to happily exist with humans on the Web. In these evaluations, we use the following summary key:
-- This technique fulfills most or all of the requirements of this evaluation criteria.
-- This technique fulfills some of the requirements of this evaluation criteria, but has some significant drawbacks.
-- This technique does not satisfy the requirements of this evaluation criteria.
Both of the parallel Web techniques that we have presented involve a data consumer retrieving alternative representations of content originally targeted for human beings. In the case of the link element, the link between the human- and machine-readable formats is contained within the HTML page itself. Therefore, the relationship is endorsed by the content creator, and we can be confident that the alternative representation is a true representation of the data shown to humans through the HTML Web page. With content negotiation, the alternative representation is chosen and returned by the Web server that controls the content, and hence we can similarly rest assured that the machine-readable data is true to the semantics of the human-oriented content.
Because the parallel Web techniques do not constrain the specific formats of alternative data representations, in theory, these techniques might provide machine-readable data that is not only equivalent but even richer in content and semantics than the original human-friendly Web page. However, we must point out that most online services use this technique to link to Atom feeds, which often only capture a small amount of the original data in machine-readable formats. For example, an Atom feed of banking transactions might capture the date, location, and title of the transaction in a machine-readable fashion, whereas the (not widely used on the parallel Web) Quicken Interchange Format contains much richer semantic data, such as account numbers, transaction types, and transaction amounts.
Our evaluation: The parallel Web provides authoritatively sound data, but in common usage does not provide machine-readable data that completely represents the authoritative human-oriented content.
The parallel Web techniques do not scale well for the purpose of expressivity and extensibility. These techniques achieve their extensibility by flexibly allowing for multiple alternative content representations. To accomplish this, however, either many URLs (in the case of the link element) or many server-side documents and their corresponding type maps (in the case of content negotiation) must be maintained. A publisher offering these techniques must also maintain code that generates each alternative representation from the underlying original data source (often data in a relational database).
All is not lost, however. Because the parallel Web techniques do not mandate one specific alternate representation, implementors are free to choose a representation that itself supports great extensibility and expressivity. In practice, however, the de facto formats used today on the Internet with parallel Web techniques do not offer much flexibility for extension to new data formats and richer semantics.
Our evaluation: The parallel Web is flexible enough to accommodate new data and new representations, but existing implementations do not scale easily and existing data formats are not particularly extensible.
The principle of "don't repeat yourself" (DRY) mandates that, if you must create both human- and machine-readable versions of data, you shouldn't need to maintain the two data formats separately. While a naive implementation of the parallel Web techniques might result in maintaining multiple files on a Web server that contain duplicate information, most real-world implementations derive the various representations from a single underlying data source (often a relational database).
In our evaluation: While the algorithms to generate the various data formats must be maintained, the actual data need only be represented a single time.
This is one area where the parallel Web lacks our support. In a scenario that makes use of the link element, the human-friendly and machine-readable versions of the relevant information are found at two different resource locations. In scenarios that make use of content negotiation, the same URL is used for both, but the human-friendly and machine-readable content are still received completely separately. In both cases, it is not usually feasible to merge and match up the data within two very different formats (for example, HTML and the Quicken Interchange Format). As such, there is no way to determine which machine-readable data corresponds with which human-oriented visual elements. Consequently, there is no easy way for humans or software to select just a small amount of content (both human and machine content) for reuse in other situations.
Our evaluation: The parallel Web provides no data locality whatsoever.
Any existing Web sites that already use content negotiation or the link element do so in a manner consistent with the parallel Web techniques described in this article. On the flip side, software that is aware of the parallel Web will not assign any additional meaning to Web pages than is already there, and therefore there is no danger of assigning incorrect semantics to existing content.
Our evaluation: The parallel Web is a technique already in use, and adopting it does not threaten the meaning of any current Web sites.
By their very nature, our parallel Web techniques are standards compliant. The link element and content negotiation are specified in the HTML and HTTP specifications, respectively, and they are widely accepted by many development communities around the world. It's also important to note the standardization of MIME types at IANA and general agreement on many of the widely used formats on the Web today. However, what is not commonly standardized is the way in which developers should expose more specific information on the content of the linked resource besides the specified MIME type, such as more information on what the feed item contents are within an Atom feed.
Our evaluation: Developers and implementors can rest assured that the parallel Web is grounded firmly in accepted standards.
The parallel Web makes heavy use of tooling to make itself attractive to developers. The Internet is filled with tooling that either directly or indirectly supports the parallel Web, making it very suitable for wider deployment. As you have seen, the Apache HTTP server contains extensive support for content negotiation; all other major Web server packages do as well. HTML editor software supports creating link elements, and Web browsers and blog-reading software supports their consumption. Additionally, given the specialty of each of the formats and the different communities supporting them, plenty of toolkits are always available in many different languages and licenses to do most of the heavy lifting during application development.
Our evaluation: The parallel Web has been around for a while and a great deal of mature tooling is available to produce and consume it.
In general, the overall complexity of employing parallel Web techniques is moderate. The concepts are rather straightforward, and -- thanks to their standards compliance and the tooling available for them -- it is not very hard to implement the techniques. Additionally, there are several advantages to separating the specification of machine-readable information from the human-readable version:
As a designer, you are freed from the need to maintain both data and presentation.
You can optimize content to suit the needs of the target consumer
At the same time, we have already touched on a few areas in which the parallel Web is more complex than other approaches. Using the link element requires that you maintain multiple URLs for multiple data representations. In a world in which one "404 Not Found" error can be the difference between a sale for you or a sale for your competitor, the maintenance of numerous active URLs can be a burdensome task. Content negotiation itself requires the maintenance of moderately complex server-side configurations. And because both techniques support multiple representations of the same data, you must write and maintain code to generate these representations from the core data.
Overall evaluation: The parallel Web is widely understood and used today, but it does require a high amount of maintenance as time passes.
Back to top
The parallel Web has long been used to further humans' experiences on the World Wide Web, and recently it has also been used a great deal to power software's ability to consume data on the Web. The parallel Web acknowledges that humans and machines have different content needs, and it keeps those needs separate by allowing some representations for humans and others for machines. It maintains those heterogeneous representations in parallel, however, either through the proliferation of many URLs united at the (human-oriented) root by the HTML link element, or by using content negotiation to mask the representations behind a single URL. The techniques that comprise the parallel Web are widely available and commonly used, and will continue to be used for the foreseeable future.
Nevertheless, you've seen in this article that both of these approaches have shortcomings that, to date, have limited them to semantically poor use cases. Use of the link element requires maintenance of multiple URLs and requires multiple HTTP requests to get at machine-readable data. Content negotiation hides different representations at a single URL and makes it difficult to unite the human view of the content with the machine view. Further, the lack of uniformity across machine-readable representations and the lack of extensibility of Atom, one of the only common machine-readable representations in use today, hamper the adoption of the parallel Web in cases such as MissMASH in which the data being produced and consumed is not consistently structured.
In the rest of this series, we'll examine techniques that strive to achieve a meaningful Web for humans and machines without maintaining two (or more) strands of a parallel Web. These techniques begin with an HTML Web page and derive semantics from the content of that page. Thus, they share the benefits of not requiring multiple URLs for multiple representations and of containing both the human- and machine-targeted content within the same payload. You will see, however, that these techniques still differ substantially in their approaches, and have their own advantages and disadvantages, which we will evaluate.
In the next article, we'll examine the algorithmic approach, in which third parties use structural and heuristic techniques to derive machine-readable semantics from HTML Web pages targeted at people.