Explore techniques for coexistence with human- and machine-friendly data
In this series of articles we'll examine the existing and emerging technologies that enable machines and humans to easily access the wealth of Web-published data. We'll discuss the need for techniques that derive the human and machine-friendly data from a single Web page. Using examples, we will explore the relationships between the different techniques and will evaluate the benefits and drawbacks of each approach. The series will examine, in detail: a parallel Web of data representations, algorithmic approaches to generating machine-readable data, microformats, GRDDL, embedded RDF, and RDFa.
In this first article, you meet the human-computer conflict, learn the criteria used to evaluate different technologies, and find a brief description of the major techniques used today to enable machine-human coexistence on the Web.
The World Wide Web empowers human beings like never before. The sheer amount and diversity of information you encounter on the Web is staggering. You can find recipes and sports scores; you share calendars and contact information; you read news stories and restaurant reviews. You can constantly consume data on the Web that's presented in a variety of appealing ways: charts and tables, diagrams and figures, paragraphs and pictures.
Yet this content-rich, human-friendly world has a shadowy underworld. It's a world in which machines attempt to benefit from this wealth of data that's so easily accessible to humans. It's the world of aggregators and agents, reasoners and visualizations, all striving to improve the productivity of their human masters. But the machines often struggle to interpret the mounds of information intended for human consumption.
The story is not all bleak, however. Even if you were unaware of this human-computer conflict, there is no need to worry. By the end of this series, you'll have enough knowledge to choose intelligently among a myriad of possible paths to bridge between the data-presentation needs of machine and human data consumers.
In the early 1990s, Tim Berners-Lee invented HTML, HTTP, and the World Wide Web. He initially designed the Web to be an information space for more than just human-to-human interactions. He intended the Web to be a semantically rich network of data that could be browsed by humans and acted upon by computer programs. This vision of the Web is still referred to as the Semantic Web.
Semantic WebA mesh of information linked up in such a way as to be easily processed by machines, on a global scale. The Semantic Web extends the Web by using standards, markup languages, and related processing tools.
However, by the very nature of its inhabitants, the Web grew exponentially and gave priority to content consumable mostly by humans and not machines. Steadily, users' lives became more reliant on the Web, and we transitioned from a Web of personal and academic homepages to a Web of e-commerce and business-to-business transactions. Even as more and more of the world's most vital information flowed through its links, most of the Web-enabled interactions still required human interpretation. But as expected, the rise of Internet-connected devices in people's lives has driven dependence on the devices' software understanding data on the Web.
Clearly, machines have interacted with each other long before the Web existed. And if the Web has come so far so quickly while primarily targeted at human consumption, it's natural to wonder what's to be gained in developing techniques for machines to share the Web with humans as an information channel. To explore this question, imagine what the current Web would look like if machines did not understand it at all.
The top three Web sites (as of this article's writing) according to Alexa traffic rankings are Yahoo!, MSN, and Google -- all search engines. Each of these sites is powered by an army of software-driven Web crawlers that apply various techniques to index human-generated Web content and make it amenable to text searches. Without these companies' vast arrays of algorithmic techniques for consuming the Web, your Web-navigation experiences would be limited to following explicitly declared hypertext links.
Next, consider the 5th most trafficked site on Alexa's list: eBay. People commonly think of eBay as one of the best examples of humans interacting on the Web. However, machines play a significant role in eBay's popularity. Approximately 47% of eBay's listings are created using software agents rather than with the human-driven forms. During the last quarter of 2005, the machine-oriented eBay platform handled eight billion service requests. Also in 2005, the number of eBay transactions through Web Services APIs increased by 84% annually. It's clear that without the services that eBay provides software agents to participate equally with humans, the online auction business would not be nearly as manageable for humans dealing with significant numbers of sales or purchases.
For a third example, we turn to Web feeds. Content-syndication formats such as Atom and RSS have empowered a new generation of news-reading software that frees you from the tedious, repetitive, and inefficient reliance on bookmarked Web sites and Web browsers to stay in touch with news of interest. Without the machine-understandable content representation embodied by RSS and Atom, these news readers could not exist.
In short, imagine a World Wide Web where a Web site could only contain content authored by humans exclusively for that site. Content could not be shared, remixed, and reused between Web sites. To intelligently aggregate, combine, and act on Web-based content, agents, crawlers, readers, and other devices must be able to read and understand that content. This is why it's necessary to take an in-depth look at the different mechanisms available today to improve the interactions between machines and human-generated content in Web applications.
Consider a scenario from the page of the Semantic Web activity at the W3C. Most people have some personal information that can be accessed on the Web. You can see your bank statements, access your online calendar applications, and post photos online through different photo-sharing services. But can you see uour photos in your calendar to remind yourself of the place and purpose of those photos? Can you see your bank-statement line items displayed in your calendar too?
Creating new data integrations of this sort requires that the software driving the integration be able to understand and interpret the data on particular Web pages. This software must be able to retrieve the Web pages that display your photos from Flickr and discover the dates, times, and descriptions of your photos. It also needs to understand how to interpret the transactions from your online bank statement. The same software must be able to understand various views of your online calendar (daily, weekly, and monthly), and figure out which parts of the Web page represent which dates and times.
The example in Figure 1 shows how embedded metadata might benefit your end-user applications. You begin with your data stored in several places. Flickr hosts your photographs, Citibank provides access to your banking transactions, and Google Calendar manages your daily schedule. You wish to experience all of this data in a single calendar-based interface (missMASH), such that the photos from your Sunday at the State Park appear in the same weekly view as your credit card transaction from Wednesday's grocery shopping. To do this, the software that powers missMASH must have some way to understand the data from your Flickr, Citibank, and Google Calendar accounts in order to remix the data in an integrated environment.
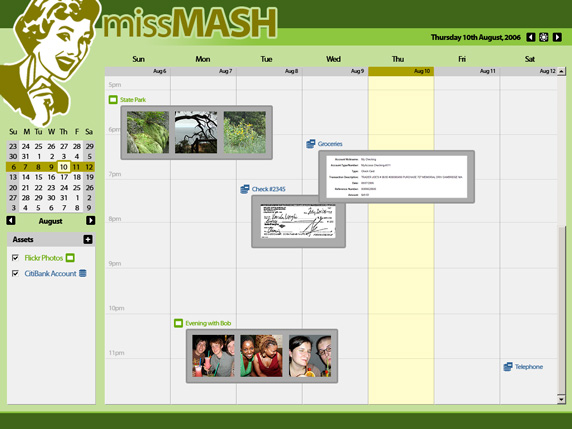
A full spectrum of technologies give application authors the ability to do such integrations. Some of the technologies are well established, while others are still fledgling and not as well understood. The barriers to entry for the technologies vary, and some of the technologies will provide a higher level of utility than others.
In this series, we'll examine how you might implement the scenario discussed above using the different mechanisms available for human-computer coexistence on the Web. We will introduce and explain each technology, then show how the technologies might be used to integrate bank statements, photos, and calendars. We will also evaluate the strengths and weaknesses of each technology, and hopefully make it easier for you to decide between the options.
Evaluation criteria
In this series, we'll examine how you might implement the scenario discussed above using the different mechanisms available for human-computer coexistence on the Web. We will introduce and explain each technology, then show how the technologies might be used to integrate bank statements, photos, and calendars. We will also evaluate the strengths and weaknesses of each technology, and hopefully make it easier for you to decide between the options.
Evaluation criteria
When you embark on a comparison of technologies, it is helpful to first outline the criteria to evaluate the technologies. The list below describes properties desirable of methods that facilitate a Web that is both human-friendly and machine-readable. We don't expect to find a single technology that succeeds in all these facets, nor should we. In the end, we hope to build a matrix that will aid you in choosing the right tool for the job. Here are the criteria we will use:
Authoritative data
Whatever the particulars are for a technique, you end up with machine-readable data that supposedly is equivalent to what shows up on the corresponding human-friendly Web page. You want the techniques that get you to that point to ensure the fidelity of this relationship; you want to be able to trust that the data really corresponds to what you read on the Web page.
The authority of the data is one axis along which to measure this trust. We consider one representation of data to be authoritative if the representation is published by the owner of the data. A data representation might be non-authoritative if it is derived from a different representation of the data by a third party.
Expressivity and extensibility
If you use one technique to create a Web page with both a human-representable and machine-readable version of directions to your home, you'd rather not need a different technique to add the weather forecast to the same Web page. We hope that this criteria will help minimize the number of software components involved in any particular application, which in turn increases the robustness and maintainability of the application.
Along these lines, we appreciate it if the techniques acommodate new data in an elegant manner, and are expressive enough to instill confidence that in the future we can represent previously unforeseen data.
Don't repeat yourself (DRY)
If the same datum is referenced twice on a Web page, you don't want to write it down twice. Repetition leads to inconsistencies when changes are required, and you don't want to jump through too many hoops to create Web pages that both humans and computers can understand.
This does not necessarily apply to repetition within multiple data representations, if those representations are generated from a single data store.
Data locality
Multiple representations of the same data within the same document should be in as self-contained a unit of the document as possible. For example, if one paragraph within a large Web page is the only part of the page that deals with the ingredients of a recipe, then you want a technique to contain all of the machine-readable data about those ingredients to that paragraph.
In addition to being easy to author and to read, data locality allows visitors to the Web page to copy and paste both the human and machine representations of the data together, rather than requiring multiple discontinuous segments of the Web page be copied to fully capture the data of interest. This, in turn, promotes wider adoption and re-use of the techniques and the data. (Just ask anyone who has ever learned HTML with the generous use of the View Source command.)
Existing content fidelity
You want the techniques to work without requiring authors to rewrite their Web sites. The more that a technique can make use of existing clues about the intended (machine-consumable) meaning of a Web page, the better. But a caveat: techniques shouldn't be so liberal with their interpretations that they ascribe incorrect meanings to existing Web pages.
For example, a new technique that prescribed that text enclosed in the HTML u tag represent the name of a publication might lead to correct semantics in some cases, but might also license many incorrect interpretations. While the markup in this example might be authoritative (because it originates from the owner of the data), it is still incorrect because the Web page author did not intend to use the u HTML tag in this manner.
Standards compliance
Tooling
Overall complexity
The Web has been around for a while now, and it's only recently that the need to share data between humans and machines is receiving a lot of attention. The vast landscapes of content available on the Web are authored and maintained by a wide variety of people, and it is important that whatever techniques we promote be easily understandable and adoptable by as many Web authors as possible.
The best techniques are as worthless as no technique if they are too complex to adopt. The most desirable techniques will have a low barrier to entry and a shallow leaning curve. They should not require extensive coding to implement, nor require painstaking efforts to maintain once implemented.
Coexistence options
This section provides a brief introduction to the major techniques used today to enable machine-human coexistence on the Web. Subsequent articles in this series will explore these techniques in detail.
Coexistence options
This section provides a brief introduction to the major techniques used today to enable machine-human coexistence on the Web. Subsequent articles in this series will explore these techniques in detail.
In this world view, the data is represented on the Web with (at least) two addresses (URLs): one address holds a human-consumable format, and one a machine-consumable format. Technologies to enable the parallel Web include the HTML link element and HTTP content negotiation. Those involved in the creation of the HTML specifications saw the need for two linking elements in HTML: the a element that is visible and can only appear in the body of a Web page, and the link element that is invisible and can only appear in the head of a Web page. The HTML specification designers reasoned that agents, depending on their purpose and target audience, would interpret the links in the head based on their rel (relationship) attribute and perform interesting functions with them.
For example, Web feeds and feed readers have empowered humans to keep up with the vast amount of information being published today. When you use a feed reader, you initialize it with the address (URL) of an XML file -- usually an RSS or Atom file. In most cases, the machine-consumable data within such a feed has a parallel URL on the Web, where you can find a human-readable representation of the same contentd. There are a variety of techniques to achieve this parallel Web in a useful and maintainable fashion. Part 2 of this series will discuss a parallel Web in detail, including the benefits and drawbacks of having the same data available at more than one Web address. Future installments of this series will cover techniques that allow multiple data representations to be contained within a single Web address.
Algorithmic approaches encompass software that produces machine-consumable data from human-readable Web pages by application of an arbitrary algorithm. In general, the algorithms tend to fall into two categories:
Scrapers, which extract data by examining the structure and layout of a Web page
Natural-language processors, which attempt to read and understand a Web page's content in order to generate data
These techniques are designed for situations where the structure or content of a Web page is highly predictable and unlikely to change. The algorithms are usually developed by the person seeking to consume the data, and as such they are not governed by any standards organization. Often, these algorithms are an integrator's only option when faced with accessing data whose owner does not publish a machine-readable representation of the data. Stay tuned for details on the algorithmic approach in Part 3 of this series.
Microformats are a series of data formats that use existing (X)HTML and CSS constructs to embed raw data within the markup of a human-targeted Web page. Microformats are guided by a set of design principles and are developed by community consensus. The Microformats community's goal is to add semantics to the existing (X)HTML class attribute, originally intended mostly for presentation.
As with the algorithmic approach, microformats differs from many others in our series because it is not part of a standards process in organizations such as the W3C or IETF. Instead, their principles focus on specific problems and leverage current behaviors and usage patterns on the Web. This has given microformats a great start towards their goal of improving Web microcontent (blogs, for example) publishing in general. The main examples of microformat success have been the hCard and hCalendar specifications. These specifications allow microcontent publishers to easily embed attributes in their HTML content that allow machines to pick out small nuggets of information, such as business cards or event information from microcontent Web sites.
Gleaning Resource Descriptions from Dialects of Languages (GRDDL) allows Web page publishers to associate their XHTML or XML documents with transformations that take the Web page as input and then output machine-consumable data. GRDDL can use XSL transformations to extract specific vocabularies from a Web page. GRDDL also allows the use of profile documents, which in turn reference the appropriate transformation algorithms for a particular class of Web pages and data vocabularies.
GRDDL has great potential for bridging the gap between humans and machines by enabling authoritative on-the-fly transformations of content. While this is similar to the parallel Web, there are significant differences. GRDDL provides a general mechanism for machines to transform content on demand, and GRDDL does not create permanent versions of alternative data representations. The W3C has recently chartered a GRDDL working group to produce a recommended specification for GRDDL.
Embedded RDF is a technique for embedding RDF data within XHTML documents using existing elements and attributes. eRDF attempts to balance ease of markup with extensibility and expressivity. Along with RDFa and, to a lesser extent, GRDDL, it explicitly makes use of the Resource Description Framework (RDF) to model the machine-consumable data that it encodes. eRDF shares with microformats the principle of reusing existing vocabularies for the purpose of embedding metadata within XHTML documents. eRDF seeks to scale beyond a small set of formats and vocabularies by using namespaces and the arbitrary RDF graph data model.
Embedded RDF is not currently developed by a standards body. Similar to microformats, eRDF is capable of encoding data within Web pages to help machines extract contact, event, and location information (and other types of data) to enable powerful software agents.
RDFa, formerly known as RDF/A, is another mechanism for including RDF data directly within XHTML. RDFa uses a fixed set of existing and new XHTML elements and attributes to allow a Web page to contain an arbitrary amount and complexity of machine-readable semantic data, alongside the standard XHTML content that is displayed to humans. RDFa is currently developed by the W3C RDF-in-XHTML task force, a joint product of the XHTML and Semantic Web Deployment working groups.
As with eRDF, RDFa takes advantage of namespaces and the RDF graph data model to enable the representation of many data structures and vocabularies within a single Web page. RDFa seeks to be a general-purpose solution to the inclusion of arbitrary machine-readable data within a Web page.
In summary
This article motivated and explained the challenge of creating a World Wide Web that is accessible to both humans and to machines. We developed an example integration scenario that could be enabled by any of the myriad of coexistence mechanisms. We also discussed the criteria with which to compare and evaluate the techniques that we will cover in more detail in the rest of this series.
Stay tuned for Part 2, which will explore in detail the widely used parallel Web technique.
No comments:
Post a Comment